| TID | Arroz | Feijão | Batata | Óleo | Água | Queijo | Vinho |
|---|---|---|---|---|---|---|---|
| 1 | y | y | n | y | n | n | n |
| 2 | n | n | n | n | n | y | y |
| 3 | y | y | y | y | n | n | n |
| 4 | y | n | n | n | y | y | y |
| 5 | y | y | y | y | n | n | n |
2 Mineração de Dados e Regras de Associação
![]()
![]()
2.1 Introdução
A Mineração de Dados é uma disciplina tão vasta que qualquer publicação sobre o tema obriga o autor a selecionar alguns tópicos em detrimento de outros não menos importantes. A atividade de Regras de Associação foi o tópico escolhido para iniciarmos a apresentação das principais atividades da Mineração de Dados por envolver ideias bem intuitivas. A analogia entre Regras de Associação e Cesta de Compras facilita o entendimento de como descobrir padrões de associação entre itens de um conjunto qualquer.
2.2 Mineração de Dados
Durante o processo de Descoberta de Conhecimento em Bases de Dados, KDD, é na etapa de Mineração de Dados que efetivamente são encontrados os padrões de associação implícitos nos dados. A análise automatizada dessa massa de dados visa detectar regularidades, ou quebra de regularidade, que constitui informação implícita, porém desconhecida, e útil para determinado fim.
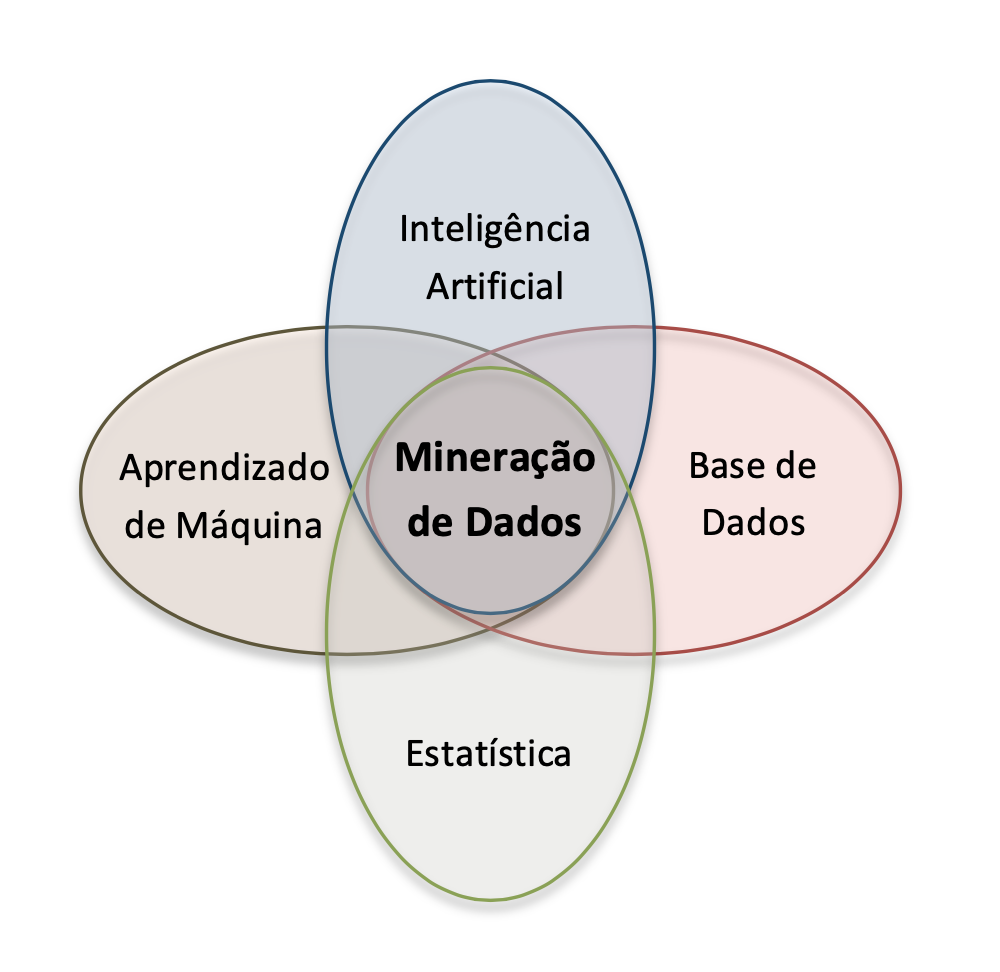
A Mineração de Dados pode ser vista como a sistematização de teorias, técnicas e algoritmos desenvolvidos em outras disciplinas já consagradas, como a Estatística, a Inteligência Artificial, o Aprendizado de Máquina, a Base de Dados etc. O propósito da Mineração de Dados é detectar automaticamente padrões de associação úteis e não óbvios em grandes quantidades de dados, veja Figura 6.2.
No dia a dia, uma quantidade incalculável de dados é gerada na forma de registros de vendas, textos brutos, imagens, sons, gráficos etc., tanto por sistemas computacionais como por seres humanos, constituindo uma espécie de informação não estruturada. Embora esta forma de registro de dados seja adequada para o ser humano, quando se trata de analisar grandes quantidades de dados de forma automatizada, é comum e conveniente que se introduza alguma estrutura que facilite o acesso e o processamento sistemático.
Para que parte de toda essa informação não estruturada possa ser utilizada na Mineração de Dados, geralmente é feita uma seleção e um pré-processamento visando transformar dados brutos em coleções estruturadas de dados. Em termos práticos, para nossas considerações iniciais, a estrutura de representação de uma Base de Dados pode ser semelhante a uma tabela de dados, sendo cada linha dessa tabela uma transação ou um exemplo. Cada transação é composta por um ou mais itens ou, visto de outra forma, cada exemplo é caracterizado por seus atributos.
As Tabelas 2.1, 2.2 e 2.3 ilustram formas de dados estruturados convenientes para a Mineração de Dados.
| TID | Itens |
|---|---|
| 1 | {Arroz, Feijão, Óleo} |
| 2 | {Queijo, Vinho} |
| 3 | {Arroz, Feijão, Batata, Óleo} |
| 4 | {Arroz, Água, Queijo, Vinho} |
| 5 | {Arroz, Feijão, Batata, Óleo} |
Na Tabela 2.1 cada uma das Transações possui uma IDentificação (TID), e seus itens representam artigos vendidos em um supermercado. Se a tabela de itens for muito extensa, como costuma ser em casos reais, pode ser ainda mais conveniente representar cada um de seus itens na forma de um atributo associado a um valor booleano, como mostra a Tabela 2.2.
Um exemplo clássico de uma Base de Dados usada em artigos sobre Mineração de Dados é apresentada na Tabela 2.3 (Quinlan (1986) apud Witten; Frank (2005)), composta por dados fictícios sobre as condições de tempo para que ocorra ou não a partida de um esporte não especificado. A tabela é composta por 14 exemplos (linhas), cada um com cinco atributos (colunas): Dia, Temperatura, Umidade, Vento e Partida. A tabela pode também ser interpretada de outra forma, como sendo composta por quatro atributos (Dia, Temperatura, Umidade e Vento) e uma classe (Partida), que representa o resultado da combinação dos quatro atributos.
| Dia | Temperatura | Umidade | Vento | Partida |
|---|---|---|---|---|
| Ensolarado | Elevada | Alta | Falso | Não |
| Ensolarado | Elevada | Alta | Verdadeiro | Não |
| Nublado | Elevada | Alta | Falso | Sim |
| Chuvoso | Amena | Alta | Falso | Sim |
| Chuvoso | Baixa | Normal | Falso | Sim |
| Chuvoso | Baixa | Normal | Verdadeiro | Não |
| Nublado | Baixa | Normal | Verdadeiro | Sim |
| Ensolarado | Amena | Alta | Falso | Não |
| Ensolarado | Baixa | Normal | Falso | Sim |
| Chuvoso | Amena | Normal | Falso | Sim |
| Ensolarado | Amena | Normal | Verdadeiro | Sim |
| Nublado | Amena | Alta | Verdadeiro | Sim |
| Nublado | Elevada | Normal | Falso | Sim |
| Chuvoso | Amena | Alta | Verdadeiro | Não |
Uma análise mais atenta dos exemplos das Tabelas 2.1 e 2.3 revela que alguns desses atributos sempre aparecem juntos e que, portanto, várias Regras de Associação podem ser extraídas dessas tabelas.
2.3 Regras de Associação
A representação do conhecimento através de regras, também conhecidas como regras IF-THEN ou Regras de Produção, é largamente utilizada porque, entre outras vantagens sobre formas alternativas de representação do conhecimento, regras são facilmente compreendidas pelo ser humano, fáceis de serem alteradas, validadas e verificadas, e de baixo custo para a criação de sistemas baseados em regras (Padhy (2010)).
\(\textcolor{blue}{\textbf{Regras de Associação}}\) são uma forma específica de representação de conhecimento que descrevem padrões de associação implícitos entre um conjunto de atributos ou itens de uma Base de Dados, e que podem ajudar a predizer com alta probabilidade a presença, ou não, de outro conjunto de atributos ou itens.
Dito de forma equivalente, uma Regra de Associação revela que a presença de um conjunto \(\mathbf{X}\) de itens numa transação implica outro conjunto \(\mathbf{Y}\) de itens, i.e., \(\mathbf{X} = \{a, b, \ldots\} \Rightarrow \mathbf{Y} = \{p, \ldots, z\}\). Note que o fato de um conjunto de itens \(\mathbf{X}\) (antecedente) estar sempre associado a outro \(\mathbf{Y}\) (consequente) não significa obrigatoriamente que um seja a causa de outro, i.e., não há necessariamente relação de causalidade entre antecedente e consequente e sim mera ocorrência simultânea de itens com certa probabilidade.
A estrutura geral de uma Regra de Associação assume a seguinte forma:
\[ \textcolor{red}{\textbf{If }} (\text{Conjunto } \mathbf{X} \text{ de Itens}) \;\textcolor{red}{\textbf{ then }}\; (\text{Conjunto } \mathbf{Y} \text{ de Itens}), \quad \text{sendo } \mathbf{X} \cap \mathbf{Y} = \varnothing \]
Com base na Tabela 2.3, várias Regras de Associação podem ser formuladas:
\[ \textcolor{red}{\textbf{If }} (\text{Temperatura} = \text{Baixa}) \;\textcolor{red}{\textbf{ then }}\; (\text{Umidade} = \text{Normal}) \tag{2.1}\]
\[ \textcolor{red}{\textbf{If }} (\text{Umidade} = \text{Normal}) \;\textcolor{red}{\textbf{ and }}\; (\text{Vento} = \text{Falso}) \;\textcolor{red}{\textbf{ then }}\; (\text{Partida} = \text{Sim}) \tag{2.2}\]
\[ \textcolor{red}{\textbf{If }} (\text{Dia} = \text{Ensolarado}) \;\textcolor{red}{\textbf{ and }}\; (\text{Partida} = \text{Não}) \;\textcolor{red}{\textbf{ then }}\; (\text{Umidade} = \text{Alta}) \tag{2.3}\]
\[ \textcolor{red}{\textbf{If }} (\text{Vento} = \text{Falso}) \;\textcolor{red}{\textbf{ and }}\; (\text{Partida} = \text{Não}) \;\textcolor{red}{\textbf{ then }}\; (\text{Temperatura} = \text{Elevada}) \;\textcolor{red}{\textbf{ and }}\; (\text{Umidade} = \text{Alta}) \tag{2.4}\]
Estas são apenas algumas das muitas Regras de Associação que podem ser formuladas com base na Tabela 2.3. Para selecionar as Regras de Associação mais representativas, i.e., aquelas que se apliquem a um grande número de exemplos com alta probabilidade de acerto, precisaremos de métricas para avaliar o alcance ou a força de cada regra. Dois dos mais conhecidos indicadores são Suporte e Confiança.
Suporte — para cada regra do tipo \(\mathbf{X} \Rightarrow \mathbf{Y}\), este parâmetro indica a quantos exemplos da tabela esta regra satisfaz (i.e., contém) tanto ao conjunto de itens de \(\mathbf{X}\) quanto ao de \(\mathbf{Y}\), ou seja, indica sua cobertura com relação ao número total \(N\) de exemplos da tabela. Portanto,
\[\mathbf{\mathbf{Sup}}\left( \mathbf{X \rightarrow Y} \right)\mathbf{=}\frac{\mathbf{|X \cup Y|}}{\mathbf{N}}\]
Por exemplo, com relação à primeira Regra 2.1, há quatro exemplos na Tabela 2.3 em que \(\mathbf{X} \cup \mathbf{Y} = \{\text{Temperatura} = \text{Baixa},\; \text{Umidade} = \text{Normal}\}\). Portanto,
\[ \mathbf{Sup}\left( \text{Regra 2.1} \right) = \frac{\left| X \cup Y \right|}{N} = \frac{\left| \left\{ \text{Temperatura = Baixa, Umidade = Normal} \right\} \right|}{N} = \frac{4}{14} = 0{,}29 \]
A Regra 2.2 também possui \(\mathbf{Sup}(\text{Regra 2.2}) = \frac{4}{14}\); a terceira regra apresenta \(\mathbf{Sup}(\text{Regra 2.3}) = \frac{3}{14}\), enquanto a quarta regra possui \(\mathbf{Sup}(\text{Regra 2.4}) = \frac{1}{14}\).
Confiança — a confiança de uma regra reflete o número de exemplos que contêm \(\mathbf{Y}\) dentre todos aqueles que contêm \(\mathbf{X}\) (veja bem, além de \(\mathbf{X} \Rightarrow \mathbf{Y}\), podem existir regras do tipo \(\mathbf{X} \Rightarrow \mathbf{Z}\), \(\mathbf{X} \Rightarrow \mathbf{W}\) etc.). Em outras palavras, o parâmetro Confiança determina quantos são os exemplos em que \(\mathbf{X}\) implica \(\mathbf{Y}\), comparado com aqueles exemplos em que \(\mathbf{X}\) pode ou não implicar \(\mathbf{Y}\). A este parâmetro costuma-se também dar o nome de \(\mathbf{Acurácia}\).
\[ \mathbf{Conf}\!\left(\mathbf{X} \Rightarrow \mathbf{Y}\right) = \frac{\left| \mathbf{X} \cup \mathbf{Y} \right|} {\left| \mathbf{X} \right|} = \frac{\mathbf{Sup}\!\left(\mathbf{X} \Rightarrow \mathbf{Y}\right)} {\mathbf{Sup}\!\left(\mathbf{X}\right)} \]
Por exemplo, com relação à primeira Regra 2.1, há quatro exemplos na Tabela 2.3 em que \(\mathbf{X} \cup \mathbf{Y} = \{\text{Temperatura} = \text{Baixa},\; \text{Umidade} = \text{Normal}\}\) e, coincidentemente, quatro exemplos em que \(\mathbf{X} = \{\text{Temperatura} = \text{Baixa}\}\). Portanto,
\[ \mathbf{Conf}\!\left(\text{Regra 2.1}\right) = \frac{\left| \mathbf{X} \cup \mathbf{Y} \right|}{\left| \mathbf{X} \right|} = \frac{\left| \{\text{Temperatura} = \text{Baixa},\; \text{Umidade} = \text{Normal}\} \right|} {\left| \{\text{Temperatura} = \text{Baixa}\} \right|} = \frac{4}{4} = 1{,}0 \]
A Regra 2.2 também possui \(\mathbf{Conf}\!\left(\text{Regra 2.2}\right) = \frac{4}{4}\); a terceira regra apresenta \(\mathbf{Conf}\!\left(\text{Regra 2.3}\right) = \frac{3}{3}\), enquanto a quarta regra possui \(\mathbf{Conf}\!\left(\text{Regra 2.4}\right) = \frac{1}{2}\).
NotaNota sobre notação: \(|\cdot|\)
Seguindo a convenção de Agrawal; Imieliński; Swami (1993) e Han; Kamber (2008), o símbolo \(|\cdot|\) nessas fórmulas não representa a cardinalidade matemática do conjunto (número de itens), mas sim a frequência absoluta — ou seja, o número de transações da base de dados que contêm aquele conjunto de itens. Assim, \(|\mathbf{X}|\) significa “quantas transações contêm todos os itens de \(\mathbf{X}\)”, equivalente a \(\mathbf{Sup}(\mathbf{X}) \times N\).
Regras de Associação são particularmente úteis para analisar o comportamento de clientes e propor “vendas casadas”. A informação de que clientes que compram o item A geralmente compram o item B pode aumentar significativamente as vendas de uma loja ou livraria, já que toda vez que um cliente manifestar a intenção de comprar o item A, a loja pode também lhe oferecer o item B.
Mas o fato de um simples conjunto de itens poder gerar muitas regras de associação faz com que o número de regras associadas a uma base de dados seja tão grande a ponto de a maioria dessas regras não ter qualquer interesse prático. Para contornar esta situação, antes de começar a gerar as regras de associação, é comum que sejam estabelecidos um valor de Suporte Mínimo (\(\mathbf{SupMin}\)) e de Confiança Mínima (\(\mathbf{ConfMin}\)). Regras com suporte muito baixo podem ser resultado de compras feitas ao acaso e, portanto, não fornecem informações de interesse. Por outro lado, regras com confiança muito baixa podem indicar que seu poder de predição é baixo e, portanto, não é muito aconselhável assumir que \(\mathbf{X}\) implica \(\mathbf{Y}\) com base nessas regras.
Agrawal; Imieliński; Swami (1993) ao introduzir o conceito de Regras de Associação propôs um algoritmo denominado Apriori no qual Regras de Associação são geradas em duas etapas:
Dado um conjunto de transações T, primeiramente são criados conjuntos de itens frequentes, chamados de Conjuntos Frequentes, que devem satisfazer o limite de \(\mathbf{SupMin}\);
a partir desses Conjuntos Frequentes são geradas Regras de Associação com confiança maior ou igual ConfMin.
2.4 Etapa 1: Geração de Conjuntos Frequentes com Suporte \(\geq \mathbf{SupMin}\)
As Tabelas 2.4 e 2.5 mostram versões simplificadas da Tabela 2.2, aqui adaptada para que cada item possa ser representado por apenas uma letra.
| TID | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 5 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| TID | Itens |
|---|---|
| 1 | {A, B, D} |
| 2 | {F, G} |
| 3 | {A, B, C, D} |
| 4 | {A, E, F, G} |
| 5 | {A, B, C, D} |
De acordo com o algoritmo Apriori, para se obter os possíveis Conjuntos Frequentes relacionados a um conjunto de transações, inicialmente devem ser criados Conjuntos Frequentes com 1 item apenas e que satisfaçam o critério de Suporte Mínimo. A seguir são criados recursivamente Conjuntos Frequentes com 2 itens, depois com 3 itens, e assim sucessivamente.
Os possíveis Conjuntos Frequentes com 1 item apenas, e seus respectivos valores de Suporte, estão representados na Tabela 2.6.
| Itens | Suporte |
|---|---|
| {A} | 4/5 |
| {B} | 3/5 |
| {C} | 2/5 |
| {D} | 3/5 |
| {E} | 1/5 |
| {F} | 2/5 |
| {G} | 2/5 |
Suponhamos que o \(\mathbf{SupMin}\) tenha sido definido como \(2/5\), ou seja, \(40\%\). De acordo com este critério, o conjunto {E} não satisfaz \(\mathbf{SupMin}\) e deve ser eliminado. Portanto os Conjuntos Frequentes com 1 Item que satisfazem o critério de \(\mathbf{SupMin}\) maior ou igual a \(2/5\) estão representados na Tabela 2.7.
Ao adotar o procedimento de poda dos candidatos a Conjunto Frequente que não satisfazem o critério de \(\mathbf{SupMin}\), o número total de Conjuntos Frequentes gerados pode cair significativamente. Em princípio, dada uma Base de Dados com \(k\) itens, o número de possíveis Conjuntos Frequentes é \(\lvert \mathbf{CF} \rvert = 2^{k} - 1\) (excluindo o conjunto vazio). Como em nossa Tabela 2.4 há 7 itens, então \(\lvert \mathbf{CF} \rvert = 2^{7} - 1 = 127\).
| Itens | Suporte |
|---|---|
| {A} | 4/5 |
| {B} | 3/5 |
| {C} | 2/5 |
| {D} | 3/5 |
| {F} | 2/5 |
| {G} | 2/5 |
A seguir devem ser formados novos Conjuntos Frequentes com 2 Itens, partindo-se dos Conjuntos Frequentes com 1 Item. Note que o Suporte de um Conjunto Frequente com 2 Itens pode ter no máximo o menor valor de Suporte de cada um de seus subconjuntos, i. e., dos respectivos Conjuntos Frequentes com 1 Item. De acordo com esta mesma propriedade, conhecida como Princípio Apriori ou antimonotônico, qualquer subconjunto de um Conjunto Frequente também será um Conjunto Frequente. Por exemplo, se \(\{A, B\}\) for um Conjunto Frequente, então \(\{A\}\) e \(\{B\}\) também são Conjuntos Frequentes e têm \(\mathbf{Suporte} \geq \mathbf{SupMin}\).
A Tabela 2.8 mostra os possíveis Conjuntos Frequentes com 2 Itens e os respectivos valores de Suporte.
Os conjuntos de 2 itens foram obtidos por combinação dos conjuntos de 1 item, enquanto que os valores de Suporte foram obtidos inspecionando-se as Tabelas 2.4 e 2.5.
Note que os detalhes de como os conjuntos de itens são efetivamente gerados dependem da forma como o algoritmo Apriori foi implementado, e diferem um pouco da exposição simplificada que se adotou aqui por razões didáticas.
Para calcular o Suporte dos Conjuntos Frequentes foi necessário ler a Base de Dados, que em nosso caso é pequena e está representada pela Tabela 2.4. Em uma implementação computacional é altamente desejável que toda a Base de Dados possa ser lida na memória principal do computador. Porém, se a Base de Dados for muito grande ela provavelmente terá de ser lida no disco rígido. Para minimizar o número de vezes que a Base de Dados é consultada, muitos candidatos a Conjuntos Frequentes podem ser inicialmente criados e depois eliminados, obtendo-se assim significativos ganhos de tempo.
| Itens | Suporte |
|---|---|
| {A, B} | 3/5 |
| {A, C} | 2/5 |
| {A, D} | 3/5 |
| {A, F} | 1/5 |
| {A, G} | 1/5 |
| {B, C} | 2/5 |
| {B, D} | 3/5 |
| {B, F} | 0 |
| {B, G} | 0 |
| {C, D} | 2/5 |
| {C, F} | 0 |
| {C, G} | 0 |
| {D, F} | 0 |
| {D, G} | 0 |
| {F, G} | 2/5 |
Para nós, neste momento, o importante é compreender como os Conjuntos Frequentes com \(k\) Itens podem ser gerados de forma relativamente simples pela combinação de Conjuntos Frequentes com \(k-1\) Itens.
Aplicando-se novamente o critério de \(\mathbf{SupMin} \geq \frac{2}{5}\), restam apenas os Conjuntos Frequentes com 2 Itens apresentados na Tabela 2.9.
| Itens | Suporte |
|---|---|
| {A, B} | 3/5 |
| {A, C} | 2/5 |
| {A, D} | 3/5 |
| {B, C} | 2/5 |
| {B, D} | 3/5 |
| {C, D} | 2/5 |
| {F, G} | 2/5 |
O próximo passo agora consiste em criar novos Conjuntos Frequentes com 3 Itens, partindo-se dos Conjuntos Frequentes com 2 Itens, cujo resultado é mostrado na Tabela 2.10.
| Itens | Suporte |
|---|---|
| {A, B, C} | 2/5 |
| {A, B, D} | 3/5 |
| {A, C, D} | 2/5 |
| {A, F, G} | 1/5 |
| {B, C, D} | 2/5 |
| {B, F, G} | 0 |
| {C, D, F} | 0 |
| {C, F, G} | 0 |
Neste caso, novamente, alguns Conjuntos Frequentes não satisfazem o critério de \(\mathbf{SupMin} \geq \frac{2}{5}\), havendo a necessidade de poda para que esses conjuntos não participem da etapa seguinte.
| Itens | Suporte |
|---|---|
| {A, B, C} | 2/5 |
| {A, B, D} | 3/5 |
| {A, C, D} | 2/5 |
| {B, C, D} | 2/5 |
Vamos agora gerar novos Conjuntos Frequentes com 4 Itens, partindo-se dos Conjuntos Frequentes com 3 Itens (Tabela 2.11), cujo resultado é mostrado na Tabela 2.12.
| Itens | Suporte |
|---|---|
| {A, B, C, D} | 2/5 |
Se houvesse ao menos dois Conjuntos Frequentes com 4 Itens poderíamos ainda tentar gerar Conjuntos Frequentes com 5 Itens. Mas como há apenas um Conjunto Frequente com 4 Itens, esta primeira etapa do algoritmo Apriori termina aqui.
2.5 Etapa 2: Geração de Regra de Associação a partir dos Conjuntos Frequentes
Uma vez obtidos os Conjuntos Frequentes com Suporte \(\geq \mathbf{SupMin}\), é possível extrair de cada Conjunto Frequente com \(k\) itens um total de \(2^{k} - 2\) Regras de Associação (excluindo-se o conjunto vazio na posição de antecedente \(\varnothing \Rightarrow \mathbf{CF}\) ou de consequente \(\mathbf{CF} \Rightarrow \varnothing\)). Na Etapa 1 foram gerados os seguintes Conjuntos Frequentes:
\[ \{A\},\; \{B\},\; \{C\},\; \{D\},\; \{F\},\; \{G\} \]
\[ \{A, B\},\; \{A, C\},\; \{A, D\},\; \{B, C\},\; \{B, D\},\; \{C, D\},\; \{F, G\} \]
\[ \{A, B, C\},\; \{A, B, D\},\; \{A, C, D\},\; \{B, C, D\} \]
\[ \{A, B, C, D\} \]
Para extrair as Regras de Associação de um Conjunto Frequente é necessário, primeiramente, gerar todos os subconjuntos não vazios desse Conjunto Frequente \(\mathbf{CF}\) e, para cada subconjunto \(\mathbf{S} \subset \mathbf{CF}\), produzir uma Regra de Associação do tipo \(\mathbf{S} \Rightarrow (\mathbf{CF} - \mathbf{S})\) que satisfaça o critério de \(\mathbf{Confiança} \geq \mathbf{ConfMin}\).
Por exemplo, dado \(\mathbf{CF} = \{A, B, C\}\), seus subconjuntos não vazios possíveis são \(\mathbf{S} = \{\{A\}, \{B\}, \{C\}, \{A, B\}, \{A, C\},\) \(\{B, C\}\}\). Portanto, é possível extrair seis Regras de Associação do \(\mathbf{CF} = \{A, B, C\}\) que envolvam os três itens:
\[ \{A\} \Rightarrow \{B, C\}, \]
\[ \{B\} \Rightarrow \{A, C\}, \]
\[ \{C\} \Rightarrow \{A, B\}, \]
\[ \{A, B\} \Rightarrow \{C\}, \]
\[ \{A, C\} \Rightarrow \{B\}, \]
\[ \{B, C\} \Rightarrow \{A\}. \]
Como o Suporte de todos os subconjuntos já terá sido calculado na Etapa 1, não será necessário percorrer novamente a Base de Dados para calcular a Confiança de cada Regra de Associação. Basta reutilizar esses valores já calculados, pois
\[ \mathbf{Conf}\!\left( \mathbf{S} \rightarrow \mathbf{CF} - \mathbf{S} \right) = \frac{\left| \mathbf{S} \cup (\mathbf{CF} - \mathbf{S}) \right|} {\left| \mathbf{S} \right|} = \frac{\left| \mathbf{CF} \right|} {\left| \mathbf{S} \right|} = \frac{\mathbf{Sup}\!\left( \mathbf{CF} \right)} {\mathbf{Sup}\!\left( \mathbf{S} \right)} \]
Voltando ao exemplo inicial da Tabela 2.5, como o Suporte de \(\mathbf{CF} = \{A, B, C\}\) é \(\frac{2}{5}\) (veja Tabela 2.11), e considerando os Suportes de seus subconjuntos,
\(\mathbf{Sup}(\{A\}) = \frac{4}{5} \quad\) (veja Tabela 2.6)
\(\mathbf{Sup}(\{B\}) = \frac{3}{5} \quad\) (veja Tabela 2.6)
\(\mathbf{Sup}(\{C\}) = \frac{2}{5} \quad\) (veja Tabela 2.6)
\(\mathbf{Sup}(\{A, B\}) = \frac{3}{5} \quad\) (veja Tabela 2.8)
\(\mathbf{Sup}(\{A, C\}) = \frac{2}{5} \quad\) (veja Tabela 2.8)
\(\mathbf{Sup}(\{B, C\}) = \frac{2}{5} \quad\) (veja Tabela 2.8)
a Confiança de cada uma das seis regras possíveis será:
\[ \mathbf{Conf}(A \Rightarrow B, C) = \frac{\frac{2}{5}}{\frac{4}{5}} = 0{,}50 \]
\[ \mathbf{Conf}(B \Rightarrow A, C) = \frac{\frac{2}{5}}{\frac{3}{5}} = 0{,}66 \]
\[ \mathbf{Conf}(C \Rightarrow A, B) = \frac{\frac{2}{5}}{\frac{2}{5}} = 1{,}00 \]
\[ \mathbf{Conf}(A, B \Rightarrow C) = \frac{\frac{2}{5}}{\frac{3}{5}} = 0{,}66 \]
\[ \mathbf{Conf}(A, C \Rightarrow B) = \frac{\frac{2}{5}}{\frac{2}{5}} = 1{,}00 \]
\[ \mathbf{Conf}(B, C \Rightarrow A) = \frac{\frac{2}{5}}{\frac{2}{5}} = 1{,}00 \]
Suponha que, para o problema em questão, tenham sido adotados \(\mathbf{SupMin} = 40\%\) e \(\mathbf{ConfMin} = 90\%\). Nesse caso, apenas três das regras acima seriam aproveitadas:
\[ \mathbf{Conf}(C \Rightarrow A, B) = 1{,}00 \quad \{Batata\} \Rightarrow \{Arroz, Feijão\} \]
\[ \mathbf{Conf}(A, C \Rightarrow B) = 1{,}00 \quad \{Arroz, Batata\} \Rightarrow \{Feijão\} \]
\[ \mathbf{Conf}(B, C \Rightarrow A) = 1{,}00 \quad \{Feijão, Batata\} \Rightarrow \{Arroz\} \]
Aplicando-se o procedimento explicado acima para todos os 18 \(\mathbf{CFs}\) obtidos na Etapa 1, seriam geradas aproximadamente 30 Regras de Associação com \(\mathbf{SupMin} = 40\%\) e \(\mathbf{ConfMin} = 90\%\) (na realidade, chegamos ao número 30 por meio de simulação no Weka, como será mostrado na Atividade Prática com o Weka).
2.6 Como Gerar Regras de Associação Usando a Ferramenta Weka
Nesta seção será apresentado um pequeno tutorial sobre a geração de Regras de Associação usando o algoritmo “Apriori” implementado na ferramenta de Aprendizado de Máquina para tarefas de Mineração de Dados Weka (Frank; Hall; Witten, 2016). A versão utilizada é a 3.6.7 (\(\textcolor{red}{\textbf{versão 3.8.6 ou 3.9.* ?}}\)). Para fazer uma simulação no Weka, a Base de Dados terá de ser escrita ou no formato CSV (Comma-Separated Value) (“.csv”) ou no formato “ARFF” (Attribute-Relation File Format), um formato bastante simples e intuitivo dessa ferramenta. Com o arquivo “.arff” carregado, podemos ajustar os parâmetros Suporte e Confiança e rodar o algoritmo Apriori.
Passo 1 - Vamos supor que nossa Base de Dados tenha sido retirada de uma planilha eletrônica (“.xls”) e salva no formato “.csv”, como mostra a Figura 2.2.
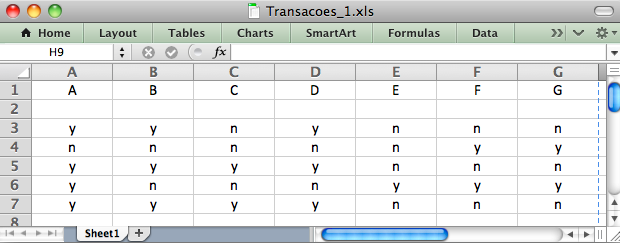
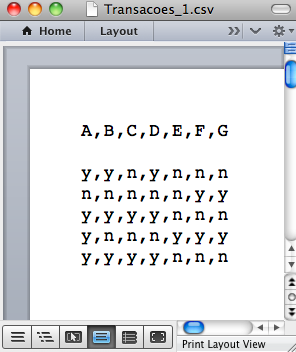
Como o Weka tem um conversor interno do formato “.csv” para “.arff”, vamos primeiramente usar este recurso. Depois vamos mostrar como transformar manualmente o arquivo “.csv” para “.arff”.
Obs.: Certifique-se que em seu arquivo “.csv” o separador de células seja efetivamente a vírgula “,” e não “;”. Se o arquivo “.csv” gerado pela sua planilha utilizar “;”, faça a substituição para “,”. Caso contrário, ocorrerá um erro de leitura no Weka e o arquivo será interpretado de forma completamente diferente do esperado.
A Tabela 2.13 apresenta a representação booleana das cestas de compras, em que cada coluna (A, B, C, …) indica a presença (y) ou ausência (n) de um item em cada transação. Esse formato é amplamente utilizado em tarefas de mineração de dados, como a extração de regras de associação.
| A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|
| y | y | n | y | n | n | n |
| n | n | n | n | n | y | y |
| y | y | y | y | n | n | n |
| y | n | n | n | y | y | y |
| y | y | y | y | n | n | n |
Instrução: Utilize o botão abaixo para baixar o arquivo
Transacoes_1.csve utilizá-lo no tutorial do Weka.
Passo 2 – Dispare o Weka (“GUI Chooser”) e tome a opção “Explorer”, que corresponde à versão com recursos gráficos e ícones (em vez de linha de comando). Veja Figura 2.3.

Passo 3 – Com a aba superior “Preprocess” escolhida, dê um clique em “Open file...”. Uma janela denominada “Open” deve se abrir. Ajuste a opção de “File Format:” para “.csv”, e escolha o arquivo “Transacoes_1.csv”, conforme mostra a Figura 2.4.
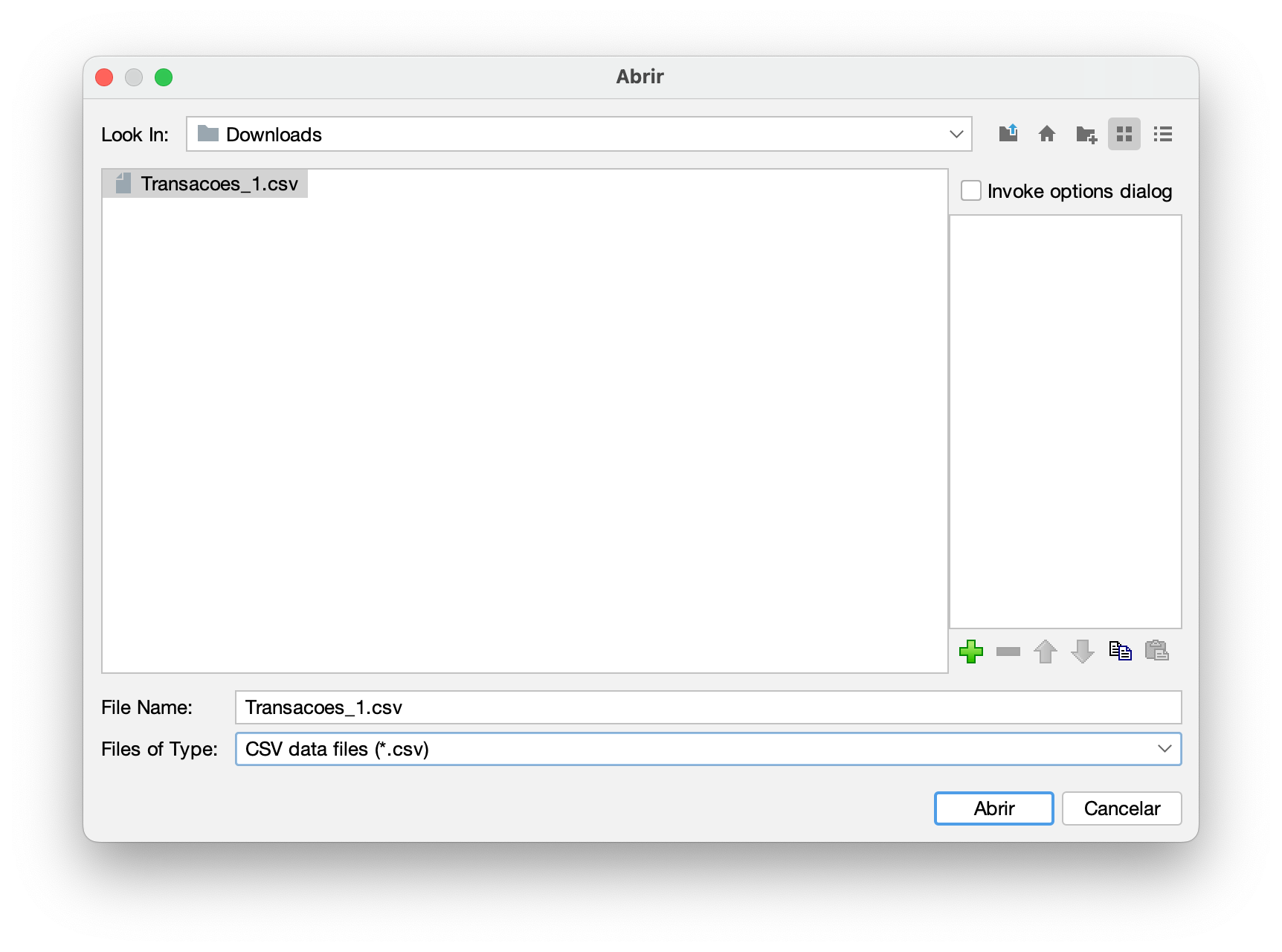
.csv.
Passo 4 – A tela do Weka Explorer deve apresentar os sete atributo do arquivo Transacoes_1, como mostra a Figura 2.5.
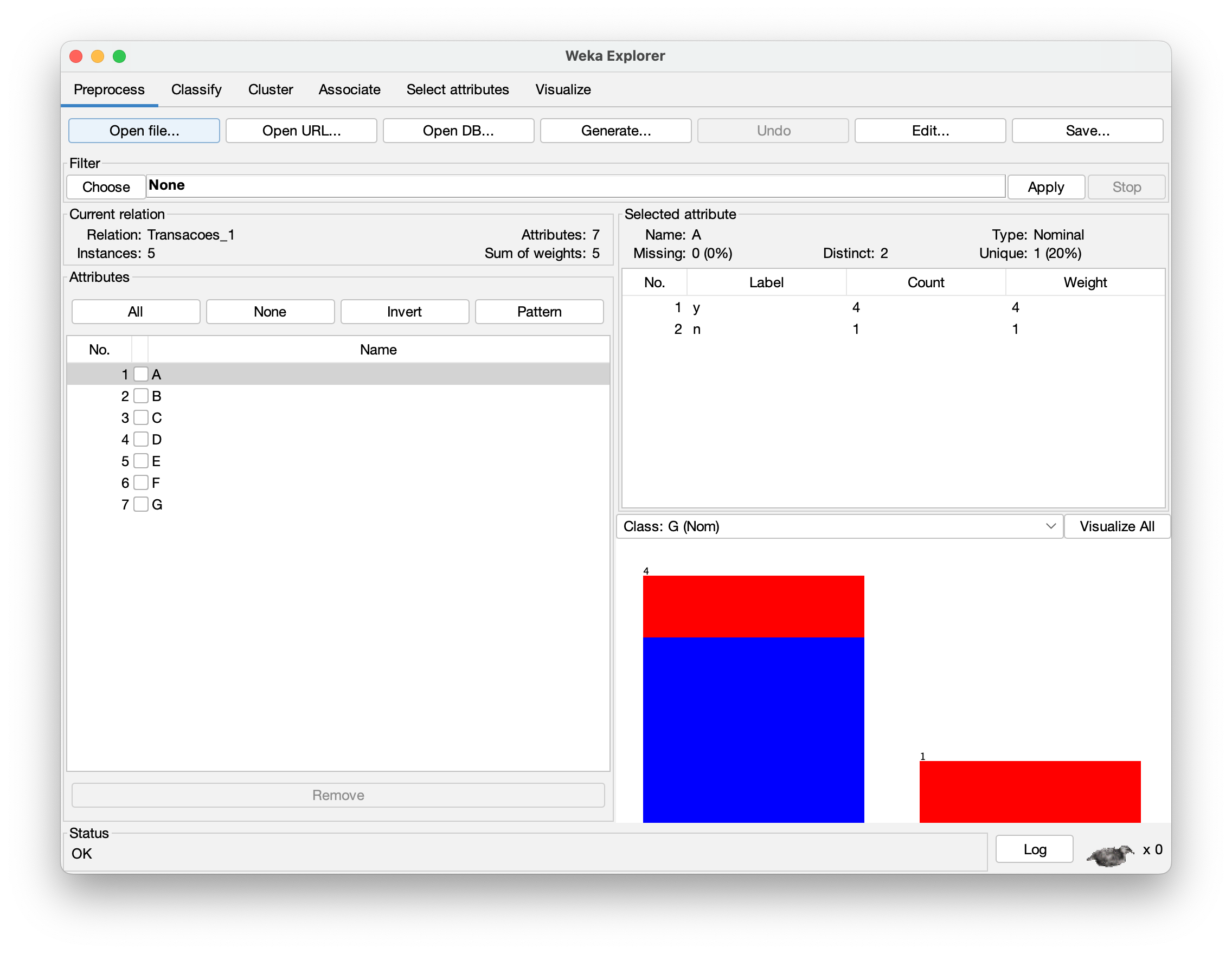
Transacoes_1 São Mostrados.
Passo 5 – Como nossa “Base de Dados” é muito pequena, a conversão manual do arquivo “.csv” para “.arff” pode ser feita muito rapidamente.
Digite no arquivo “Transacoes_1.csv” as palavras-chave “@relation”, “@attribute” e “@data”, de acordo com a Figura 2.6, salve e feche o arquivo “.csv”. Mude a terminação do arquivo de “.csv” para “.arff”. Há ainda outras alternativas: Crie um arquivo “Transacoes_1.txt” com o conteúdo mostrado abaixo na Figura 2.6 (certifique-se de que se trata efetivamente de arquivo tipo “.txt” e não, por exemplo, “Transacoes_1.txt.doc” ou “Transacoes_1.txt.rtf”). Feche o arquivo e mude a terminação para “.arff”, ou seja, para “Transacoes_1.arff”.
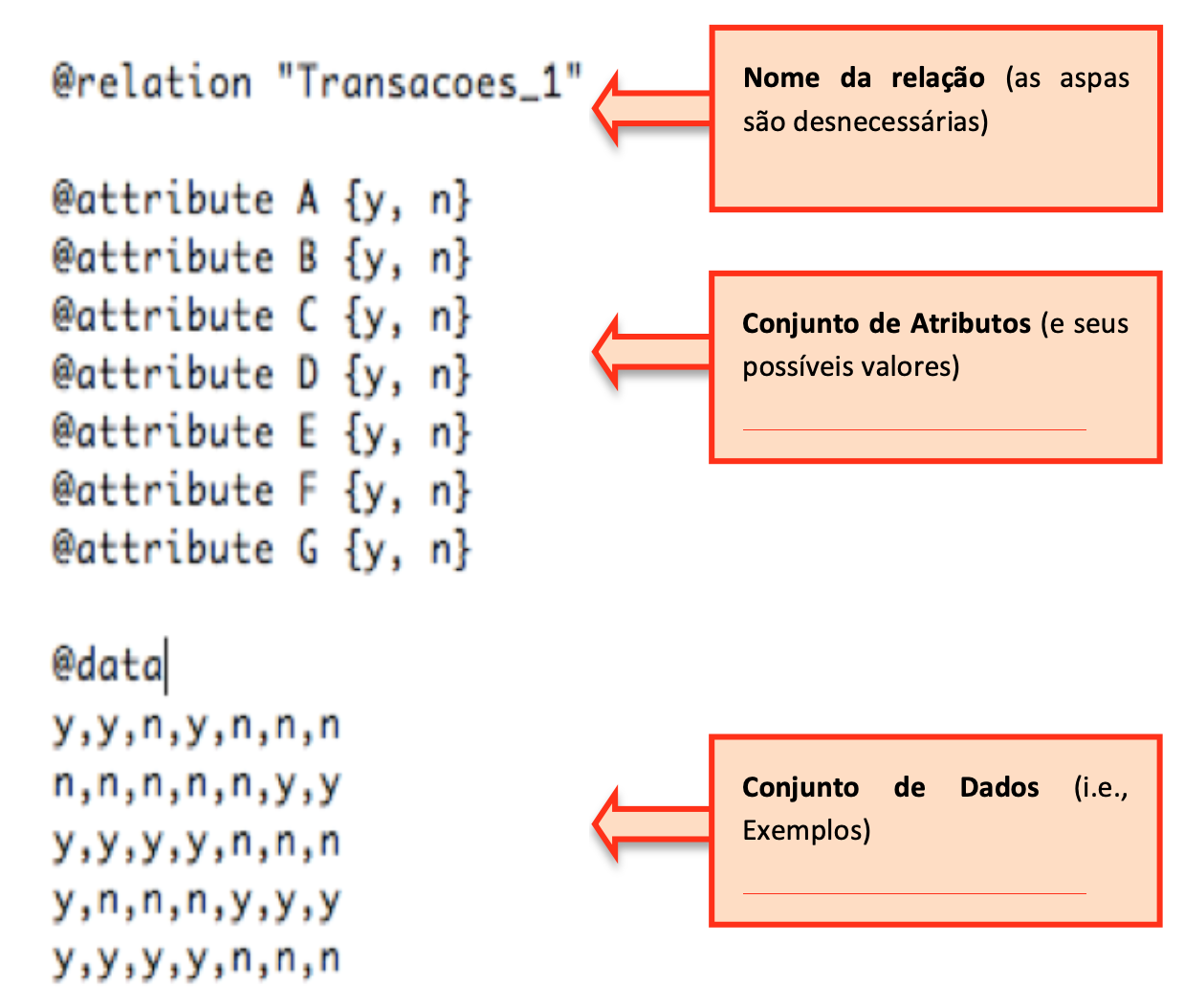
Instrução: Utilize o botão abaixo para baixar o arquivo
Transacoes_1.arffe utilizá-lo no tutorial do Weka.
Passo 6 – Com o arquivo “Transacoes_1.arff” pronto, disparar o Weka, selecionar a aba “Preprocess”, depois clicar na opção “Open file...” e escolher o arquivo “Transacoes1_.arff”, conforme mostra a Figura 2.7.
Passo 7 – Depois de abrir o arquivo “Transacoes_1.arff”, ainda com a aba “Preprocess” selecionada, escolha “No class” (ao lado de “Visualize all”), conforme ilustra a Figura 2.8. (Como vamos gerar Regras de Associação, qualquer um dos atributos pode funcionar como “classe”. Este conceito vai ser melhor explicado quando formos estudar Regras de Classificação.).
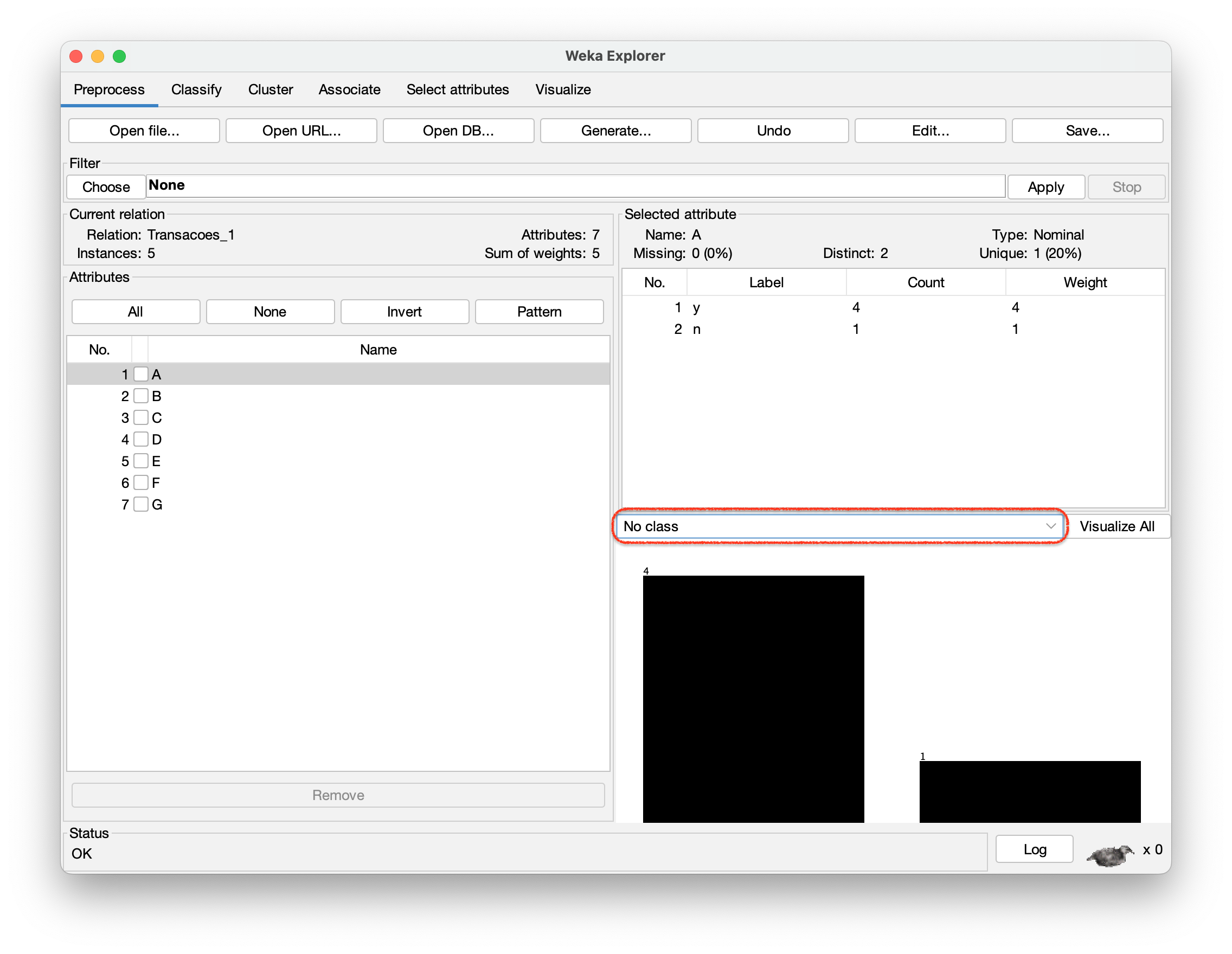
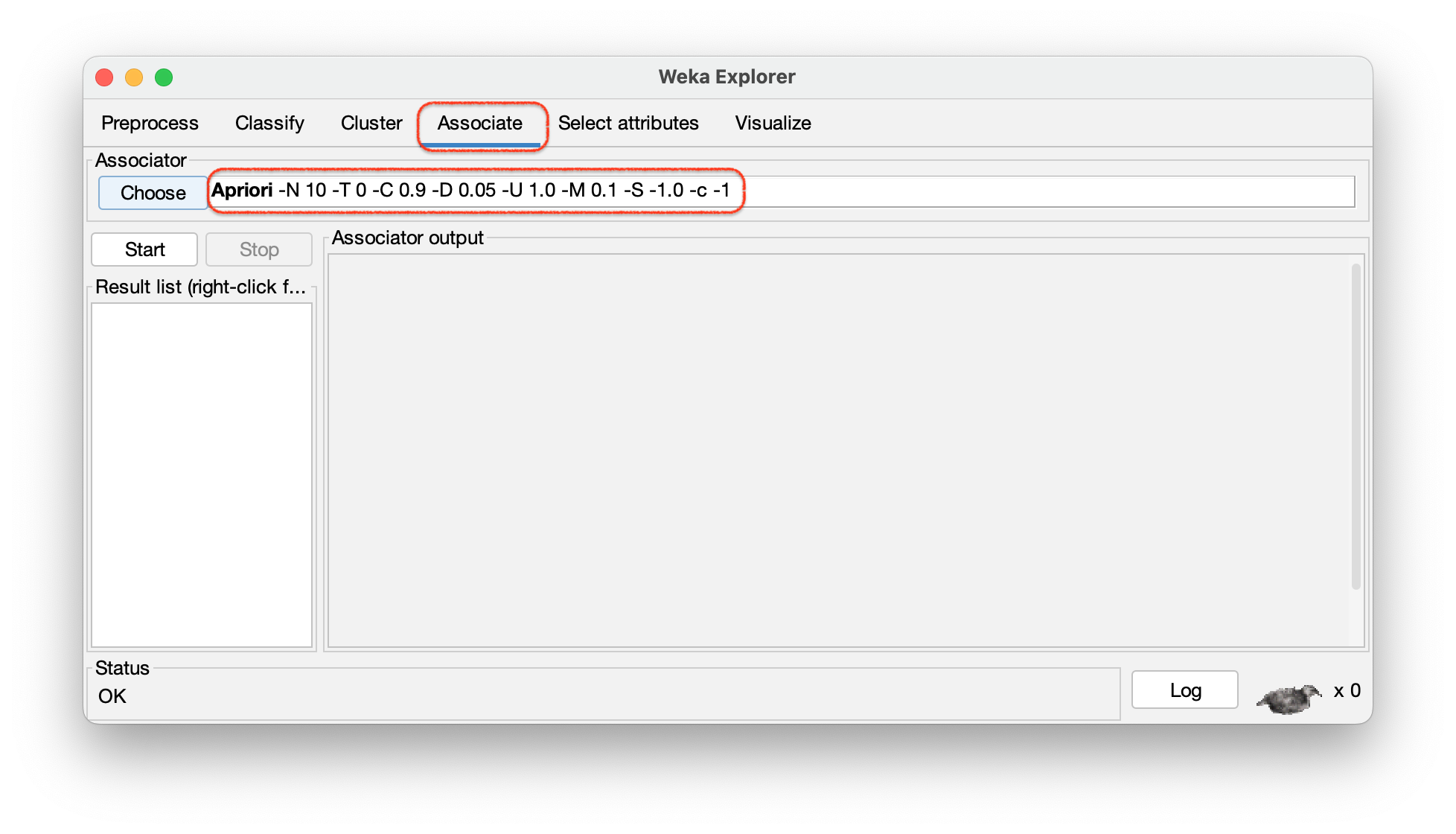
Passo 8 – Na aba superior do Weka, escolher “Associate” e ao lado de “Choose” clicar duas vezes sobre o algoritmo “Apriori”, conforme mostra a Figura 2.9.
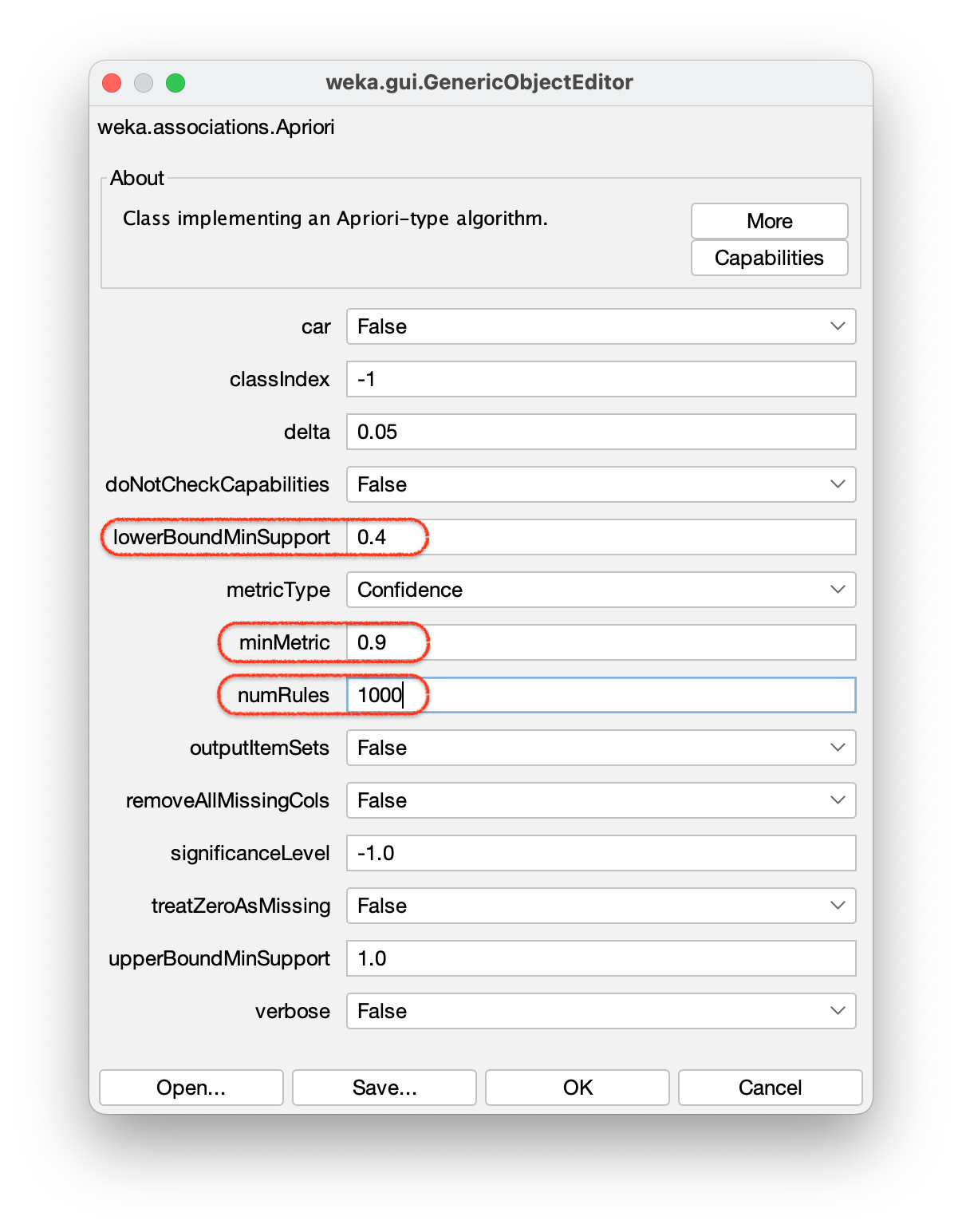
Passo 9 – Na janela que se abre, ajustar o \(\mathbf{SupMin}\) (“lowerBoundMinSupport”) para 0.4, a ConfMin (minMetric) para 0.9 e o número de regras mostradas (“numRules”) para 1000, conforme mostra a Figura 2.10. Clicar em “OK”.
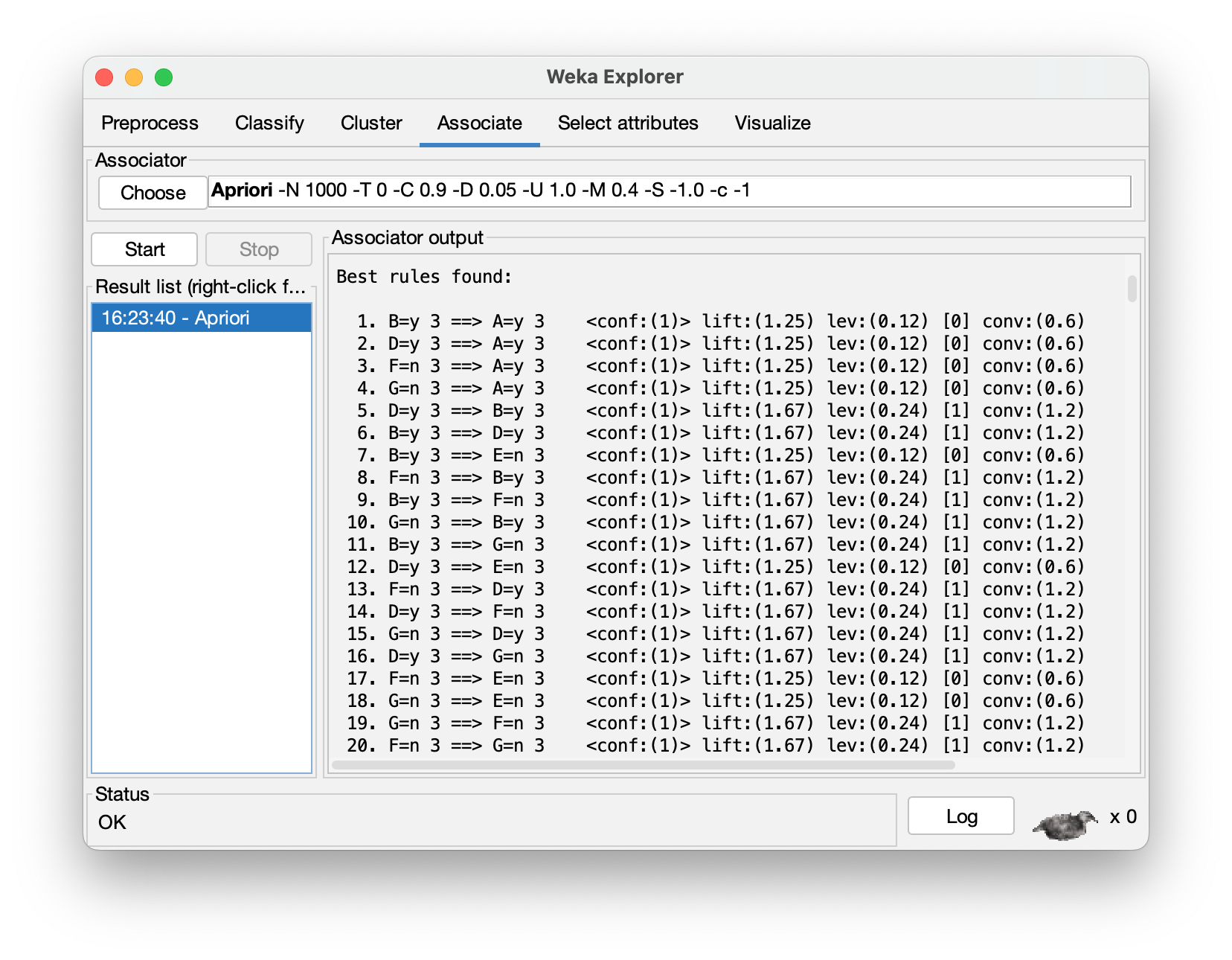
Passo 10 – Ao clicar em “Start” (ver Figura 2.9) centenas de Regras de Associação serão geradas, a maioria delas sem qualquer interesse, conforme ilustra a Figura 2.11. Um dos riscos da geração de Regras de Associação é que muitas delas podem não ter qualquer significado prático. Para contornar este tipo de problema, é possível introduzir pequenas mudanças na forma como os atributos são declarados e reduzir significativamente o número de regras geradas.
Passo 11 – Uma forma de diminuir o número de regras é substituir os valores ausentes de atributo “n” por “?”. Crie um arquivo “Transacoes_2.arff” conforme mostra a Figura 2.12.

Instrução: Utilize o botão abaixo para baixar o arquivo
Transacoes_2.arffe utilizá-lo no tutorial do Weka.
Isso evitará que o Weka crie regras sem qualquer significado prático, envolvendo itens ausentes, como por exemplo \(\{F = n\} \Rightarrow \{G = n\}\) (Regra 20 na Figura 2.11). Embora a regra \(\{F = y\} \Rightarrow \{G = y\}\) (isto é, “quem compra queijo também costuma comprar vinho”) possa ser de interesse, a regra segundo a qual “quem não compra queijo também não compra vinho” dificilmente trará alguma informação prática. Em uma Base de Dados muito grande, regras desse tipo podem aparecer em quantidades proibitivamente elevadas.
Com o arquivo “Transacoes_2.arff” foram geradas 30 Regras de Associação (Figura 2.13), sendo que as regras ilustrativas do texto teórico do Capítulo 2, envolvendo o \(\mathbf{CF} = \{A, B, C\}\), aparecem na Figura 2.13 como as regras 15, 16 e 17.
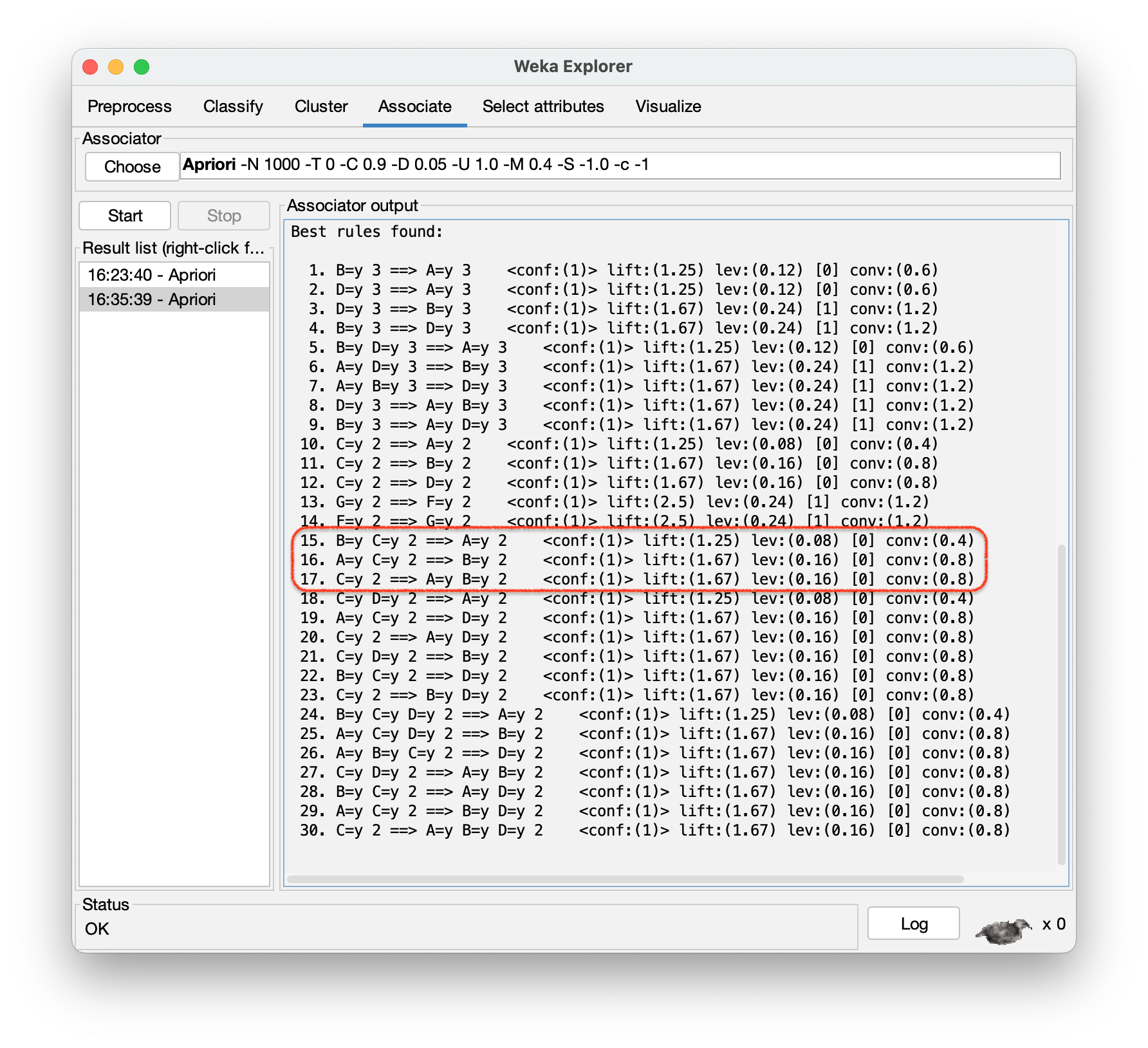
Há outras formas de melhorar a qualidade dos resultados e controlar o número de regras geradas, por exemplo, através do parâmetro \(\mathbf{Lift}\), cujo significado fica como lição de casa.
2.7 🧪 Prática em Python
A atividade de Regras de Associação foi o tópico escolhido para iniciarmos as principais atividades da Mineração de Dados por envolver ideias bem intuitivas. A analogia entre Regras de Associação e Cesta de Compras facilita o entendimento de como descobrir padrões de associação entre itens de um conjunto qualquer.
Uma Regra de Associação possui a forma:
\[\mathbf{X} \Rightarrow \mathbf{Y}, \quad \text{sendo } \mathbf{X} \cap \mathbf{Y} = \varnothing\]
onde \(\mathbf{X}\) é o antecedente e \(\mathbf{Y}\) o consequente. Note que a associação não implica causalidade — apenas ocorrência simultânea com certa probabilidade.
2.7.1 🔹 Configuração do Ambiente
Retomamos o padrão do capítulo anterior: todos os import no topo, verificação de versões e uso de dicionários para estruturar os dados antes de convertê-los em DataFrames.
ImportanteAtenção: Dependência de Execução
O conteúdo deste capítulo é sequencial. As funções, variáveis e datasets definidos nas células são requisitos para as práticas seguintes.
Certifique-se de executar as células de forma sequencial; caso contrário, as células posteriores apresentarão erros de “variável não definida” (NameError).
# ============================================================
# BLOCO DE IMPORTAÇÕES
# ============================================================
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
!pip install networkx -q --no-cache-dir 2>/dev/null
import sys
import re
import numpy as np
import pandas as pd
import networkx as nx
from itertools import combinations
import matplotlib
import matplotlib.pyplot as plt
from IPython.display import Markdown
from dataclasses import dataclass, field
print(f"Python : {sys.version.split()[0]}")
print(f"Pandas : {pd.__version__}")
print(f"NumPy : {np.__version__}")
print(f"Networkx : {nx.__version__}")
print(f"Matplotlib: {matplotlib.__version__}")
print("✅ Ambiente pronto!")Python : 3.9.7
Pandas : 2.3.3
NumPy : 2.0.2
Networkx : 3.2.1
Matplotlib: 3.9.4
✅ Ambiente pronto!2.7.2 🔹 Prática 1 — Itemsets de Tamanho 1 (\(L_1\))
O primeiro passo da mineração é identificar a relevância individual de cada item. Para isso, transformamos a contagem bruta em Suporte (\(\mathbf{Sup_0}\)), que representa a frequência relativa de um item no conjunto total de transações (\(N\)).
Nesta etapa, aplicamos o conceito de Poda (Pruning):
Se definirmos um suporte mínimo de 40%, qualquer item com frequência inferior a esse limiar (como a Água, que possui apenas 20% de suporte no dataset deste capítulo) é descartado.
Por que podar? Pela propriedade do Apriori, se a “Água” é não frequente sozinha, qualquer combinação que a inclua (como “Água e Pão”) também será infrequente. Isso economiza processamento ao ignorar caminhos sem potencial.
2.7.2.1 A Métrica de Cobertura
O cálculo do suporte para um item (ou conjunto) \(X\) é dado por:
\[\mathbf{Sup_0}(X) = \frac{\text{frequência de } X}{N}\]
- Suporte: Mede a cobertura (popularidade). Indica quão representativo aquele item é na base de dados.
O resultado da análise de frequência e a aplicação do critério de poda para itens individuais podem ser observados na Tabela 2.14, gerada pelo código a seguir, que detalha o suporte de cada item e seu status de aceitação.
# 1. Dados e Representação
transacoes_raw = [
{"Arroz", "Feijão", "Óleo"},
{"Queijo", "Vinho"},
{"Arroz", "Feijão", "Batata", "Óleo"},
{"Arroz", "Água", "Queijo", "Vinho"},
{"Arroz", "Feijão", "Batata", "Óleo"}
]
transacoes = [frozenset(t) for t in transacoes_raw]
# Todos os itens na ordem utilizada neste capítulo
todos_itens = ["Arroz", "Feijão", "Batata", "Óleo", "Água", "Queijo", "Vinho"]
# 2. Função de Suporte (Base para as próximas práticas)
def calcular_suporte(itemset, transacoes):
if not isinstance(itemset, (frozenset, set)):
itemset = frozenset([itemset]) if isinstance(itemset, str) else frozenset(itemset)
# Contagem de transações que contêm o itemset
contagem = sum(1 for t in transacoes if itemset.issubset(t))
return contagem / len(transacoes)
# 3. Análise do L1 e Poda
SUP_MIN = 0.4
l1_frequentes = []
resultados_l1 = []
for item in todos_itens:
sup = calcular_suporte(item, transacoes)
status = "ACEITO" if sup >= SUP_MIN else "PODADO"
if sup >= SUP_MIN:
l1_frequentes.append(item)
# Armazena os dados para o DataFrame
resultados_l1.append({
"Item": item,
"Suporte": f"{sup:.1%}",
"Status": status
})
# 4. Exibição Tabular
df_l1 = pd.DataFrame(resultados_l1)
print(f"Configuração: Suporte Mínimo = {SUP_MIN:.0%}\n")
# 5. Ordem descendente pelo Suporte
df_l1 = df_l1.sort_values(by="Suporte", ascending=False)
Markdown(df_l1.to_markdown(index=False, colalign=("center",) * len(df_l1.columns)))Configuração: Suporte Mínimo = 40%
| Item | Suporte | Status |
|---|---|---|
| Arroz | 80.0% | ACEITO |
| Feijão | 60.0% | ACEITO |
| Óleo | 60.0% | ACEITO |
| Batata | 40.0% | ACEITO |
| Queijo | 40.0% | ACEITO |
| Vinho | 40.0% | ACEITO |
| Água | 20.0% | PODADO |
2.7.3 🔹 Prática 2 — Itemsets de Tamanho 2 (\(L_2\)) e Regras Direcionadas
Após identificarmos os itens isolados que possuem relevância (\(L_1\)), avançamos para a formação de pares (\(L_2\)). O objetivo aqui é descobrir não apenas o que se vende, mas o que se vende junto.
Nesta etapa, a eficiência da poda torna-se evidente: utilizamos apenas os itens aprovados na etapa anterior para gerar combinações. Itens descartados (como a Água) não entram nos novos testes, reduzindo o esforço computacional. Para validar se um par constitui uma regra forte, acrescentamos a Confiança:
\[\mathbf{Sup}(X \Rightarrow Y) = \frac{|X \cup Y|}{N}\]
\[\mathbf{Conf}(X \Rightarrow Y) = \frac{\mathbf{Sup}(X \cup Y)}{\mathbf{Sup}(X)}\]
- Suporte (\(\mathbf{Sup}\)): Indica a cobertura (popularidade do par no dataset).
- Confiança (\(\mathbf{Conf}\)): Indica a precisão ou assertividade. É a probabilidade de o item \(Y\) estar presente, dado que o item \(X\) já foi adquirido.
Após a filtragem dos itens individuais, geramos as combinações de pares e calculamos sua precisão, conforme apresentado na Tabela 2.15, gerada com a execução do código a seguir, que lista as regras candidatas e seu respectivo suporte e confiança.
ImportanteAtenção: Dependência de Execução
Esta prática é incremental e depende da execução da Prática 1 (função calcular_suporte, lista l1_frequentes e SUP_MIN) e das bibliotecas já importadas.
# 1. Função de Confiança
def calcular_confianca(antecedente, consequente, transacoes):
sup_total = calcular_suporte(frozenset(antecedente) | frozenset(consequente), transacoes)
sup_ant = calcular_suporte(antecedente, transacoes)
return sup_total / sup_ant if sup_ant > 0 else 0.0
# 2. Configuração de Limiares
CONF_MIN = 0.9
resultados_l2 = []
l2_frequentes_set = set() # Usar set para evitar duplicatas de pares (A,B == B,A)
# 3. Geração de Regras e Poda
for combo in combinations(l1_frequentes, 2):
itemset_par = frozenset(combo)
sup_par = calcular_suporte(itemset_par, transacoes)
# Só processamos se o par em si for frequente (Critério L2)
if sup_par >= SUP_MIN:
itens = list(itemset_par)
# Testamos as duas direções da regra: ant -> cons
for ant, cons in [(itens[0], itens[1]), (itens[1], itens[0])]:
conf = calcular_confianca([ant], [cons], transacoes)
# DEFINIÇÃO DO STATUS (Inclusão em L2 ocorre aqui)
if conf >= CONF_MIN:
status = "ACEITO"
l2_frequentes_set.add(itemset_par) # Adiciona ao L2 real
else:
status = "PODADO"
resultados_l2.append({
"Regra": f"{ant} → {cons}",
"Suporte": f"{sup_par:.0%}",
"Confiança": f"{conf:.2f}",
"Status": status
})
# Lista final de L2 para o próximo passo (L3)
l2_frequentes = list(l2_frequentes_set)
# 4. Exibição Tabular
df_l2 = pd.DataFrame(resultados_l2)
print(f"Configuração: Suporte Mínimo = {SUP_MIN:.0%}, Confiança Mínima = {CONF_MIN:.0%}\n")
# 5. Ordenação e Markdown
if not df_l2.empty:
df_l2 = df_l2.sort_values(by=["Status", "Confiança"], ascending=[True, False])
display(Markdown(df_l2.to_markdown(index=False, colalign=("center",) * len(df_l2.columns))))
else:
print("Nenhuma regra gerada para os parâmetros atuais.")Configuração: Suporte Mínimo = 40%, Confiança Mínima = 90%
| Regra | Suporte | Confiança | Status |
|---|---|---|---|
| Feijão → Arroz | 60% | 1 | ACEITO |
| Batata → Arroz | 40% | 1 | ACEITO |
| Óleo → Arroz | 60% | 1 | ACEITO |
| Batata → Feijão | 40% | 1 | ACEITO |
| Óleo → Feijão | 60% | 1 | ACEITO |
| Feijão → Óleo | 60% | 1 | ACEITO |
| Batata → Óleo | 40% | 1 | ACEITO |
| Vinho → Queijo | 40% | 1 | ACEITO |
| Queijo → Vinho | 40% | 1 | ACEITO |
| Arroz → Feijão | 60% | 0.75 | PODADO |
| Arroz → Óleo | 60% | 0.75 | PODADO |
| Feijão → Batata | 40% | 0.67 | PODADO |
| Óleo → Batata | 40% | 0.67 | PODADO |
| Arroz → Batata | 40% | 0.5 | PODADO |
2.7.4 🔹 Prática 3 — Itemsets de Tamanho 3 (\(L_3\)) e Visualização
À medida que aumentamos o tamanho dos conjuntos para trios (\(L_3\)), a análise torna-se mais rica: buscamos regras onde a presença de dois itens “puxa” um terceiro. Introduzimos aqui o Grafo de Associação, uma ferramenta visual quando as tabelas começam a ficar extensas, permitindo identificar o fluxo lógico das decisões de compra.
A evolução para conjuntos de três itens e a validação de regras compostas são apresentadas na Tabela 2.16, gerada com a execução do código a seguir.
ImportanteAtenção: Dependência de Execução
Esta prática depende das funções e das listas de itens frequentes geradas nas Práticas 1 e 2 e das bibliotecas já importadas.
# 1. Configuração de Candidatos
# trios_candidatos = [frozenset(c) for c in combinations(l1_frequentes, 3)]
trios_candidatos = []
# Comparamos cada par com todos os outros
for i in range(len(l2_frequentes)):
for j in range(i + 1, len(l2_frequentes)):
# Une dois pares (ex: {Arroz, Feijão} + {Arroz, Óleo} = {Arroz, Feijão, Óleo})
candidato = l2_frequentes[i] | l2_frequentes[j]
# Só nos interessam uniões que resultem em exatamente 3 itens
if len(candidato) == 3 and candidato not in trios_candidatos:
# PODA: Verificamos se TODOS os subconjuntos de 2 itens deste trio são frequentes
subconjuntos = [frozenset(c) for c in combinations(candidato, 2)]
if all(s in l2_frequentes for s in subconjuntos):
trios_candidatos.append(candidato)
print(f"Trios de candidatos gerados via L1: {len(list(combinations(l1_frequentes, 3)))}")
print(f"Trios de candidatos gerados via L2 (com poda): {len(trios_candidatos)}")
print([", ".join(sorted(list(c))) for c in trios_candidatos])
resultados_l3 = []
G_L3 = nx.DiGraph() # Grafo auxiliar para o próximo bloco
# 2. Mineração de Trios e Regras
for trio in trios_candidatos:
sup_trio = calcular_suporte(trio, transacoes)
if sup_trio >= SUP_MIN:
itens = sorted(list(trio))
for combo in combinations(itens, 2):
ant = frozenset(combo)
cons = trio - ant
conf = calcular_confianca(ant, cons, transacoes)
ant_str = ", ".join(sorted(list(ant)))
cons_str = ", ".join(sorted(list(cons)))
if conf >= CONF_MIN:
status = "ACEITO"
G_L3.add_edge(ant_str, cons_str, weight=conf)
else:
status = "PODADO"
resultados_l3.append({
# .join() transforma a lista em string, removendo [] e ''
"Itemset (L3)": ", ".join(sorted(list(trio))),
"Regra": f"{{{ant_str}}} → {{{cons_str}}}",
"Suporte": f"{sup_trio:.0%}",
"Confiança": f"{conf:.2f}",
"Status": status
})
# 3. Exibição Tabular
df_l3 = pd.DataFrame(resultados_l3)
print(f"Configuração: SUP_MIN {SUP_MIN:.0%} | CONF_MIN: {CONF_MIN:.0%}\n")
# 4. Ordem descendente pela Confiança
df_l3 = df_l3.sort_values(by="Confiança", ascending=False)
Markdown(df_l3.to_markdown(index=False, colalign=("center",) * len(df_l3.columns)))Trios de candidatos gerados via L1: 20
Trios de candidatos gerados via L2 (com poda): 4
['Arroz, Batata, Feijão', 'Batata, Feijão, Óleo', 'Arroz, Batata, Óleo', 'Arroz, Feijão, Óleo']
Configuração: SUP_MIN 40% | CONF_MIN: 90%
| Itemset (L3) | Regra | Suporte | Confiança | Status |
|---|---|---|---|---|
| Arroz, Batata, Feijão | {Arroz, Batata} → {Feijão} | 40% | 1 | ACEITO |
| Arroz, Batata, Feijão | {Batata, Feijão} → {Arroz} | 40% | 1 | ACEITO |
| Batata, Feijão, Óleo | {Batata, Feijão} → {Óleo} | 40% | 1 | ACEITO |
| Batata, Feijão, Óleo | {Batata, Óleo} → {Feijão} | 40% | 1 | ACEITO |
| Arroz, Batata, Óleo | {Arroz, Batata} → {Óleo} | 40% | 1 | ACEITO |
| Arroz, Batata, Óleo | {Batata, Óleo} → {Arroz} | 40% | 1 | ACEITO |
| Arroz, Feijão, Óleo | {Arroz, Feijão} → {Óleo} | 60% | 1 | ACEITO |
| Arroz, Feijão, Óleo | {Arroz, Óleo} → {Feijão} | 60% | 1 | ACEITO |
| Arroz, Feijão, Óleo | {Feijão, Óleo} → {Arroz} | 60% | 1 | ACEITO |
| Arroz, Batata, Feijão | {Arroz, Feijão} → {Batata} | 40% | 0.67 | PODADO |
| Batata, Feijão, Óleo | {Feijão, Óleo} → {Batata} | 40% | 0.67 | PODADO |
| Arroz, Batata, Óleo | {Arroz, Óleo} → {Batata} | 40% | 0.67 | PODADO |
Para facilitar a compreensão das interdependências entre esses trios, as regras aceitas são mapeadas visualmente no grafo da Figura 2.14, gerado com a execução do código a seguir.
# 4. Visualização do Grafo (Apenas para as Regras ACEITAS)
if not G_L3.edges():
print("\nNenhuma regra L3 atingiu os critérios para exibição no grafo.")
else:
plt.figure(figsize=(10, 5))
# Seed fixo para garantir que o layout seja reproduzível
pos = nx.spring_layout(G_L3, k=1.5, seed=41)
# Desenho dos nós e labels
nx.draw_networkx_labels(G_L3, pos, font_size=10, font_weight="bold")
# Desenho das arestas com curvatura para evitar sobreposição de regras bidirecionais
nx.draw_networkx_edges(G_L3, pos, arrowstyle='->', arrowsize=30, edge_color='skyblue',
connectionstyle="arc3,rad=0.1", width=2)
# Labels de Confiança (em vermelho) sobre as arestas
edge_labels = {k: f"{v:.2f}" for k, v in nx.get_edge_attributes(G_L3, 'weight').items()}
nx.draw_networkx_edge_labels(G_L3, pos,
edge_labels=edge_labels, font_color='red', font_size=9)
plt.title("Mapa de Fluxo L3 (Regras de Trios ACEITAS)")
plt.axis('off')
plt.show()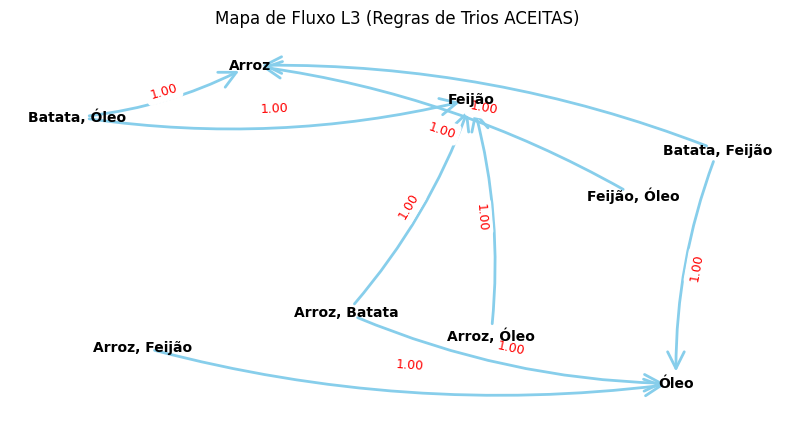
2.7.4.1 💡 Destaques Didáticos desta Etapa:
Assimetria e Comportamento de Compra: A análise das regras (ver Tabela 2.16) mostra que a Batata atua como um forte “item de entrada”. Ela garante 100% de confiança como antecedente (direcionando a compra de outros itens), mas falha como consequente (sendo podada com 67% de confiança). Isso indica que a Batata é um item planejado: o consumidor vai à loja buscá-la, mas raramente a compra por impulso motivado por outros produtos.
Poda Ativa (Propriedade Apriori): Aplicamos a poda real onde um trio só é testado se todos os seus pares internos forem frequentes em \(L_2\). Isso demonstra como o algoritmo reduz drasticamente o espaço de busca, ignorando combinações que matematicamente não atingiriam o suporte mínimo.
Eficiência Computacional: A filtragem de candidatos antes do cálculo de suporte evidencia a economia de recursos. Neste exemplo, reduzimos de 20 para apenas 4 trios candidatos a serem verificados na base de dados, viabilizando a mineração em grandes volumes.
Escalabilidade: O processo de \(L_3\) para \(L_4\) segue a mesma lógica. À medida que o tamanho dos conjuntos aumenta, o “funil” estatístico torna-se mais estreito, restando apenas as associações mais robustas e estrategicamente relevantes para o negócio.
Para consolidar esse aprendizado e evitar a repetição manual de blocos de código para cada nível, apresentamos a seguir uma implementação generalizada. Este código automatiza a descoberta de todos os conjuntos frequentes (\(L_i\)) de forma iterativa, prosseguindo até que não restem mais candidatos que satisfaçam os limiares de suporte e confiança definidos.
2.7.5 🔹 Prática 4 — Algoritmo Apriori Completo e a Métrica Lift
O algoritmo Apriori fundamenta-se na propriedade anti-monotônica do suporte: se um conjunto de itens é infrequente, todos os seus superconjuntos (combinações maiores) também o serão. Isso permite “podar” o espaço de busca, evitando que o computador teste combinações inúteis em grandes bases de dados.
2.7.5.1 🧮 Interpretação do Lift (Elevação)
O \(\mathbf{Lift}\) é o “filtro de realidade” da análise de associação. Ele indica se a relação entre dois itens é uma conexão real ou apenas coincidência estatística devido à popularidade de um deles. O cálculo compara a probabilidade de \(Y\) ocorrer quando \(X\) está presente, contra a probabilidade de \(Y\) ocorrer sozinho:
- \(\mathbf{Sup}(Y)\) ou \(P(Y)\): É a chance geral de alguém levar \(Y\) (a popularidade basal).
- \(\mathbf{Conf}(X \Rightarrow Y)\) ou \(P(Y|X)\): É a chance de levar \(Y\) dado que \(X\) já está no carrinho.
- \(\mathbf{Lift}\):
\[\mathbf{Lift}(X \Rightarrow Y) = \frac{\mathbf{Conf}(X \Rightarrow Y)}{\mathbf{Sup}(Y)} = \frac{P(Y|X)}{P(Y)}\]
- \(\mathbf{Lift} > 1\): O item \(X\) realmente impulsiona a venda de \(Y\). Há uma relação de valor (associação positiva).
- \(\mathbf{Lift} \approx 1\): A relação é aleatória. \(Y\) é comprado com ou sem \(X\) na mesma proporção.
- \(\mathbf{Lift} < 1\): Efeito de substituição. Quem compra \(X\) tende a não comprar \(Y\) (associação negativa).
2.7.5.2 Implementação: Automação e Relatório de Inteligência
O código abaixo integra a descoberta iterativa de itemsets (loop \(L_1, L_2, L_3, \dots, L_n\)), a validação de confiança e o cálculo de \(\mathbf{Lift}\), exibindo o status final de cada regra. O relatório consolidado de todas as regras encontradas pelo algoritmo, priorizadas pela força de associação, é exibido na Tabela 2.17, ordenado pela coluna \(\mathbf{Lift}\) decrescente.
ImportanteAtenção: Dependência de Execução
Esta prática é dependente das funções calcular_suporte, calcular_confianca e da variável transacoes definidas nas Práticas 1 e 2, além das bibliotecas importadas na configuração do ambiente. Certifique-se de ter executado as células anteriores.
@dataclass
class RegraAssociacao:
antecedente: frozenset
consequente: frozenset
suporte: float
confianca: float
lift: float = 0.0
def apriori(transacoes, sup_min, conf_min):
# Dicionário para armazenar suportes já calculados: {itemset: valor}
suportes_cache = {}
n_transacoes = len(transacoes)
def get_suporte(itemset):
if itemset not in suportes_cache:
count = sum(1 for t in transacoes if itemset.issubset(t))
suportes_cache[itemset] = count / n_transacoes
return suportes_cache[itemset]
itens = sorted(set().union(*transacoes))
frequentes = []
# L1: Itens individuais
candidatos_k = [frozenset([i]) for i in itens]
# Etapa 1: Itemsets Frequentes (Geração e Poda)
while candidatos_k:
# Filtro de Suporte: Identifica quem é frequente no nível atual
freq_k = [c for c in candidatos_k if get_suporte(c) >= sup_min]
frequentes.extend(freq_k)
if not freq_k: break
# Gerar Candidatos para o próximo nível (k + 1)
k_proximo = len(freq_k[0]) + 1
freq_set = set(freq_k) # Set para busca rápida O(1)
# união (Join)
candidatos_brutos = {a | b for a, b in combinations(freq_k, 2)
if len(a | b) == k_proximo}
# PODA (Pruning): Só mantém o candidato se
# TODOS os seus subconjuntos de tamanho k forem frequentes
candidatos_k = []
for cand in candidatos_brutos:
subconjuntos = [frozenset(c) for c in combinations(cand, k_proximo - 1)]
if all(s in freq_set for s in subconjuntos):
candidatos_k.append(cand)
# Etapa 2: Regras de Associação
regras_aceitas = []
dados_relatorio = []
for itemset in frequentes:
if len(itemset) < 2: continue
# Para cada subconjunto do itemset frequente
# (Gera regras muitos-para-um e muitos-para-muitos)
for tam_ant in range(1, len(itemset)):
for ant_tuple in combinations(itemset, tam_ant):
ant = frozenset(ant_tuple)
con = itemset - ant
sup_total = get_suporte(itemset)
sup_ant = get_suporte(ant)
sup_con = get_suporte(con)
# Cálculos de métricas
conf = sup_total / sup_ant
# Lift: Confiança dividida pelo suporte basal do consequente
lift = conf / sup_con if sup_con > 0 else 0.0
status = "ACEITO" if conf >= conf_min else "PODADO"
regra = RegraAssociacao(ant, con, sup_total, conf, lift)
if conf >= conf_min:
regras_aceitas.append(regra)
# Formatação para o relatório
ant_str = ", ".join(sorted(list(ant)))
con_str = ", ".join(sorted(list(con)))
dados_relatorio.append({
"Regra": f"{{{ant_str}}} → {{{con_str}}}",
"Suporte": f"{regra.suporte:.0%}",
"Confiança": f"{regra.confianca:.2f}",
"Lift": f"{regra.lift:.2f}",
"Status": status
})
return regras_aceitas, dados_relatorio
# --- Execução ---
regras_finais, relatorio_lista = apriori(transacoes, SUP_MIN, CONF_MIN)
# Criar DataFrame e ordenar decrescentemente pelo Lift (força da regra)
df_final = pd.DataFrame(relatorio_lista)
if not df_final.empty:
df_final['Lift_Num'] = df_final['Lift'].astype(float)
df_final = df_final.sort_values(by='Lift_Num', ascending=False).drop(columns=['Lift_Num'])
print(f"RELATÓRIO APRIORI COMPLETO (N={len(transacoes)}, SUP_MIN={SUP_MIN}, \
CONF_MIN={CONF_MIN})\n")
Markdown(df_final.to_markdown(index=False, colalign=("center",) * len(df_final.columns)))RELATÓRIO APRIORI COMPLETO (N=5, SUP_MIN=0.4, CONF_MIN=0.9)
| Regra | Suporte | Confiança | Lift | Status |
|---|---|---|---|---|
| {Vinho} → {Queijo} | 40% | 1 | 2.5 | ACEITO |
| {Queijo} → {Vinho} | 40% | 1 | 2.5 | ACEITO |
| {Batata} → {Feijão} | 40% | 1 | 1.67 | ACEITO |
| {Feijão} → {Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Arroz, Óleo} → {Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Arroz, Batata} → {Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Batata} → {Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Óleo} → {Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Óleo} → {Feijão} | 60% | 1 | 1.67 | ACEITO |
| {Feijão} → {Óleo} | 60% | 1 | 1.67 | ACEITO |
| {Óleo} → {Arroz, Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Batata} → {Arroz, Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Feijão} → {Arroz, Óleo} | 60% | 1 | 1.67 | ACEITO |
| {Arroz, Óleo} → {Feijão} | 60% | 1 | 1.67 | ACEITO |
| {Arroz, Feijão} → {Óleo} | 60% | 1 | 1.67 | ACEITO |
| {Óleo} → {Arroz, Feijão} | 60% | 1 | 1.67 | ACEITO |
| {Arroz, Feijão} → {Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Arroz, Batata} → {Feijão} | 40% | 1 | 1.67 | ACEITO |
| {Feijão} → {Arroz, Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Batata} → {Arroz, Feijão} | 40% | 1 | 1.67 | ACEITO |
| {Arroz, Feijão, Óleo} → {Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Arroz, Óleo} → {Batata, Feijão} | 40% | 0.67 | 1.67 | PODADO |
| {Batata, Óleo} → {Arroz, Feijão} | 40% | 1 | 1.67 | ACEITO |
| {Arroz, Batata} → {Feijão, Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Batata} → {Arroz, Feijão, Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Feijão, Óleo} → {Arroz, Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Arroz, Feijão} → {Batata, Óleo} | 40% | 0.67 | 1.67 | PODADO |
| {Batata, Feijão} → {Arroz, Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Feijão} → {Batata, Óleo} | 40% | 0.67 | 1.67 | PODADO |
| {Batata} → {Feijão, Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Batata, Óleo} → {Feijão} | 40% | 1 | 1.67 | ACEITO |
| {Óleo} → {Batata, Feijão} | 40% | 0.67 | 1.67 | PODADO |
| {Óleo} → {Arroz, Batata, Feijão} | 40% | 0.67 | 1.67 | PODADO |
| {Feijão} → {Arroz, Batata, Óleo} | 40% | 0.67 | 1.67 | PODADO |
| {Batata, Feijão} → {Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Feijão, Óleo} → {Batata} | 40% | 0.67 | 1.67 | PODADO |
| {Arroz, Batata, Óleo} → {Feijão} | 40% | 1 | 1.67 | ACEITO |
| {Arroz, Batata, Feijão} → {Óleo} | 40% | 1 | 1.67 | ACEITO |
| {Feijão} → {Arroz} | 60% | 1 | 1.25 | ACEITO |
| {Arroz} → {Feijão} | 60% | 0.75 | 1.25 | PODADO |
| {Óleo} → {Arroz} | 60% | 1 | 1.25 | ACEITO |
| {Arroz} → {Óleo} | 60% | 0.75 | 1.25 | PODADO |
| {Batata} → {Arroz} | 40% | 1 | 1.25 | ACEITO |
| {Arroz} → {Batata} | 40% | 0.5 | 1.25 | PODADO |
| {Arroz} → {Batata, Óleo} | 40% | 0.5 | 1.25 | PODADO |
| {Batata, Óleo} → {Arroz} | 40% | 1 | 1.25 | ACEITO |
| {Batata, Feijão} → {Arroz} | 40% | 1 | 1.25 | ACEITO |
| {Arroz} → {Feijão, Óleo} | 60% | 0.75 | 1.25 | PODADO |
| {Feijão, Óleo} → {Arroz} | 60% | 1 | 1.25 | ACEITO |
| {Arroz} → {Batata, Feijão} | 40% | 0.5 | 1.25 | PODADO |
| {Arroz} → {Batata, Feijão, Óleo} | 40% | 0.5 | 1.25 | PODADO |
| {Batata, Feijão, Óleo} → {Arroz} | 40% | 1 | 1.25 | ACEITO |
Por fim, a Figura 2.15 apresenta o grafo de influência final, onde a graduação de cores destaca o valor estratégico (\(\mathbf{Lift}\)) de cada associação descoberta.
# --- Grafo de Lift (Apenas regras ACEITAS) ---
G_final = nx.DiGraph()
for r in regras_finais:
G_final.add_edge(", ".join(sorted(r.antecedente)),
", ".join(sorted(r.consequente)), weight=r.lift)
if not G_final.edges():
print("\nNenhuma regra atingiu os critérios para exibição no grafo.")
else:
plt.figure(figsize=(12, 6))
pos = nx.spring_layout(G_final, k=2.5, seed=1)
lifts = [G_final[u][v]['weight'] for u, v in G_final.edges()]
nx.draw_networkx_labels(G_final, pos, font_size=10, font_weight='bold')
# Mapeamento de cores baseado no Lift
sm = plt.cm.ScalarMappable(cmap=plt.cm.Reds,
norm=plt.Normalize(vmin=min(lifts), vmax=max(lifts)))
nx.draw_networkx_edges(G_final, pos, edge_color=lifts, edge_cmap=plt.cm.Reds, width=2,
arrowsize=25, connectionstyle="arc3,rad=0.2")
plt.colorbar(sm, ax=plt.gca(), label='Lift (Força da Associação)')
plt.axis('off')
plt.show()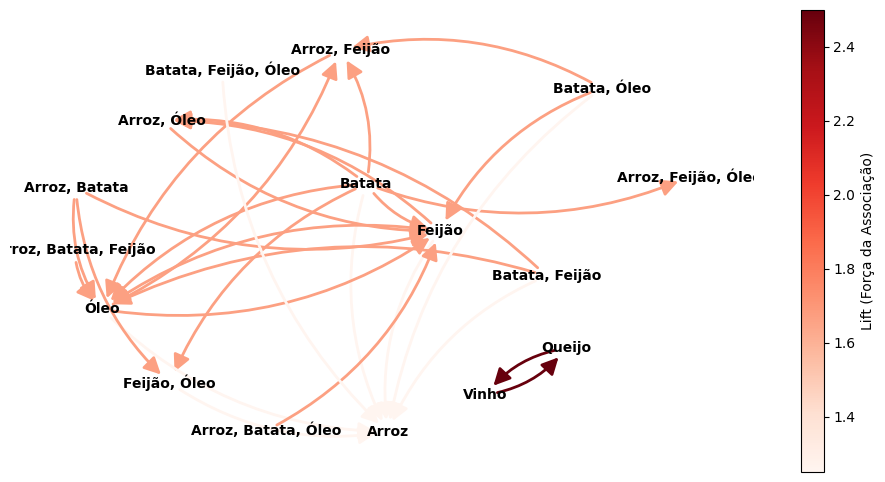
Desafio: Nesta Prática 4, o código gera candidatos e testa o suporte na base de dados. Como poderíamos alterar a função para que ela descarte um candidato se um de seus subconjuntos não for frequente, sem precisar consultar a base de dados?
2.7.6 🔹 Prática 5 — Biblioteca MLxtend
A biblioteca MLxtend contém implementações otimizadas do Apriori e também do FP-Growth (que é ainda mais rápido).
Instalação:
!pip install mlxtend -q --no-cache-dir 2>/dev/null2.7.6.1 Implementação Direta
O uso dessas bibliotecas requer um pré-processamento para converter a lista de transações em uma matriz booleana (One-Hot Encoding). A Tabela 2.18 apresenta o resultado gerado pelo código a seguir. Caso esteja utilizando o Colab ou Jupyter Notebook, execute o código abaixo e, em uma nova célula, imprima a variável te_ary para visualizar a estrutura da matriz lógica. As funções da biblioteca MLxtend utilizadas são:
apriori(): Identifica os itemsets frequentes (combinações de produtos). O parâmetromin_support=0.4define que apenas combinações que aparecem em pelo menos 40% das transações serão consideradas. Ouse_colnames=Trueé fundamental para que o resultado exiba os nomes dos produtos (ex: “Arroz”) em vez de índices numéricos, facilitando a interpretação.association_rules(): Gera as regras de associação (Se A, então B) a partir dos itemsets encontrados anteriormente. O uso demetric="confidence"commin_threshold=0.9atua como um filtro de qualidade rigoroso: apenas regras com 90% de precisão (confiança) ou mais são mantidas no relatório final, garantindo que a associação seja estatisticamente confiável.
from mlxtend.frequent_patterns import apriori, association_rules
from mlxtend.preprocessing import TransactionEncoder
# 1. Dados de exemplo
dataset = [["Arroz", "Feijão", "Óleo"],
["Queijo", "Vinho"],
["Arroz", "Feijão", "Batata", "Óleo"],
["Arroz", "Água", "Vinho", "Queijo"],
["Arroz", "Feijão", "Batata", "Óleo"]]
# 2. Processamento MLxtend
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)
regras = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.9)
# --- RELATÓRIO ---
# 3. Preparação do DataFrame Final
df_final = regras[['antecedents', 'consequents', 'support', 'confidence', 'lift']].copy()
# ORDENAÇÃO: Sempre antes de formatar como string para garantir precisão matemática
df_final = df_final.sort_values(by='lift', ascending=False)
# LIMPEZA E JUNÇÃO: Criando a coluna única "Regra"
df_final['Regra'] = df_final.apply(
lambda x: f"{{{', '.join(list(x['antecedents']))}}} → \
{{{', '.join(list(x['consequents']))}}}",
axis=1
)
# SELEÇÃO DE COLUNAS: Mantendo apenas a Regra e as métricas
df_final = df_final[['Regra', 'support', 'confidence', 'lift']]
df_final.columns = ['Regra', 'Suporte', 'Confiança', 'Lift']
# --- FORMATAÇÃO VISUAL ---
df_final['Suporte'] = df_final['Suporte'].map('{:.1%}'.format)
df_final['Confiança'] = df_final['Confiança'].map('{:.2f}'.format)
df_final['Lift'] = df_final['Lift'].map('{:.2f}'.format)
# 4. Exibição do Relatório
Markdown(df_final.to_markdown(index=False, colalign=("center",) * len(df_final.columns)))| Regra | Suporte | Confiança | Lift |
|---|---|---|---|
| {Queijo} → {Vinho} | 40.0% | 1 | 2.5 |
| {Vinho} → {Queijo} | 40.0% | 1 | 2.5 |
| {Óleo} → {Feijão} | 60.0% | 1 | 1.67 |
| {Feijão} → {Óleo} | 60.0% | 1 | 1.67 |
| {Batata} → {Óleo} | 40.0% | 1 | 1.67 |
| {Batata} → {Feijão} | 40.0% | 1 | 1.67 |
| {Batata} → {Arroz, Feijão} | 40.0% | 1 | 1.67 |
| {Arroz, Batata} → {Óleo} | 40.0% | 1 | 1.67 |
| {Arroz, Batata} → {Feijão} | 40.0% | 1 | 1.67 |
| {Óleo, Batata} → {Feijão} | 40.0% | 1 | 1.67 |
| {Óleo} → {Arroz, Feijão} | 60.0% | 1 | 1.67 |
| {Arroz, Feijão} → {Óleo} | 60.0% | 1 | 1.67 |
| {Óleo, Arroz} → {Feijão} | 60.0% | 1 | 1.67 |
| {Batata} → {Óleo, Arroz} | 40.0% | 1 | 1.67 |
| {Batata, Feijão} → {Óleo, Arroz} | 40.0% | 1 | 1.67 |
| {Óleo, Arroz, Batata} → {Feijão} | 40.0% | 1 | 1.67 |
| {Arroz, Batata, Feijão} → {Óleo} | 40.0% | 1 | 1.67 |
| {Óleo, Batata} → {Arroz, Feijão} | 40.0% | 1 | 1.67 |
| {Batata} → {Óleo, Arroz, Feijão} | 40.0% | 1 | 1.67 |
| {Feijão} → {Óleo, Arroz} | 60.0% | 1 | 1.67 |
| {Batata, Feijão} → {Óleo} | 40.0% | 1 | 1.67 |
| {Batata} → {Óleo, Feijão} | 40.0% | 1 | 1.67 |
| {Arroz, Batata} → {Óleo, Feijão} | 40.0% | 1 | 1.67 |
| {Óleo, Batata} → {Arroz} | 40.0% | 1 | 1.25 |
| {Feijão} → {Arroz} | 60.0% | 1 | 1.25 |
| {Óleo} → {Arroz} | 60.0% | 1 | 1.25 |
| {Batata} → {Arroz} | 40.0% | 1 | 1.25 |
| {Batata, Feijão} → {Arroz} | 40.0% | 1 | 1.25 |
| {Óleo, Feijão} → {Arroz} | 60.0% | 1 | 1.25 |
| {Óleo, Batata, Feijão} → {Arroz} | 40.0% | 1 | 1.25 |
2.7.6.2 Outras Bibliotecas
Além da MLxtend, existem outras opções dependendo do seu volume de dados:
- PyCaret: É uma biblioteca de Low-Code. Com apenas duas linhas (
setupecreate_model), ela faz todo o processo acima e ainda gera gráficos interativos. É excelente para quem quer rapidez. - Apyori: Uma biblioteca bem simples e leve, que não depende do Pandas ou Scikit-learn. É boa para scripts rápidos onde você não quer instalar dependências pesadas.
- Efficient-Apriori: Focada em performance e memória, permite passar as transações como um gerador Python (bom para arquivos CSV tão grandes que não cabem na memória RAM).
2.7.6.3 Comparação com este capítulo
Ao usar a MLxtend, você ganha:
- Performance: Capaz de lidar com milhares de itens e transações em segundos.
- Métricas Extras: Além de Suporte, Confiança e Lift, ela calcula automaticamente o Leverage e a Conviction.
- Integração com Pandas: O resultado já é um DataFrame.
2.7.7 Conclusão do Ciclo de Aprendizado
Através destas cinco práticas, percorremos desde a organização de dados brutos até a mineração avançada e otimizada. Vimos que a Mineração de Regras de Associação não é uma busca cega, mas um processo científico baseado em:
- Poda (Pruning): Redução drástica do esforço computacional ao ignorar candidatos improváveis.
- Métricas (Sup, Conf, Lift): Filtros estatísticos que separam o ruído do conhecimento real e valioso.
- Visualização (Grafos): Ferramentas que permitem ao analista ignorar o óbvio e focar em padrões de alto valor estratégico para o negócio.
2.8 🤖 Uso do NotebookLM como Tutor Complementar
Seguindo o padrão do capítulo anterior, além dos notebooks interativos no Google Colab, incentiva-se o uso do NotebookLM como ferramenta complementar de aprendizagem. Essa ferramenta de IA utiliza exclusivamente os documentos fornecidos pelos autores como base de conhecimento, garantindo respostas alinhadas ao conteúdo do livro.
Para cada capítulo, foi preparado um projeto específico na plataforma. Para uma experiência de estudo ampliada, utilize o acesso abaixo:
2.9 Considerações Finais
Um conjunto de Regras de Associação constitui uma forma de conhecimento extraído de uma Base de Dados, sendo esta representação do conhecimento geralmente um tipo de aprendizado muito útil para aplicações práticas, como o aumento de vendas de uma rede de supermercados, o projeto de catálogos de novos produtos ou o lançamento de campanhas promocionais baseadas em vendas casadas. Geralmente quando fazemos busca na Web, ao digitarmos uma palavra de busca é comum que outras palavras sejam sugeridas. Isso ocorre porque a ferramenta de busca está usando Regras de Associação e tem em sua Base de Dados registros de que pessoas que buscam a Palavra_1 geralmente buscam também a Palavra_2, a Palavra_3, e assim por diante.
Nesta primeira abordagem da extração de conhecimento a partir de uma Base de Dados foi suficiente apenas um procedimento algoritmo, sem necessidade de inferências. Nos próximos capítulos vamos mostrar que na prática é comum nos depararmos com situações para as quais não se conhece um algoritmo que produza o conhecimento necessário para uma tomada de decisão. Para estes casos, será necessário pensar num mecanismo de inferência que nos permita chegar à conclusão mais plausível para determinada situação. Esse é o caso de sistemas conhecidos como Sistemas Especialistas, que auxiliam por exemplo um médico a fazer diagnóstico a partir dos sintomas do paciente. Como nem sempre os sintomas declarados pelo paciente são compatíveis com determinada doença, ou então porque o paciente omite determinados sintomas importantes para o diagnóstico correto, o sistema precisa fazer inferências comparando sua Base [permanente] de Conhecimento com os sintomas declarados.
Regras de Associação frequentemente usam atributos nominais (por exemplo, temperatura elevada, amena, baixa) e mais raramente atributos numéricos (por exemplo \(40^\circ\mathrm{C},\; 23^\circ\mathrm{C},\; 4^\circ\mathrm{C}\)), porque algoritmos para extração de Regras de Associação com atributos numéricos não costumam apresentar bom desempenho em grandes Bases de Dados. Além disso, ao não levar em conta por exemplo o preço de um artigo ou a quantidade de itens vendidos em cada transação, as Regras de Associação geralmente se transformam numa forma simplista de representação do conhecimento extraído da Base de Dados.
No exemplo da Cesta de Artigos mostramos como gerar Regras de Associação que indiquem venda casada dos artigos mais comum. Mas, frequentemente, os especialistas em vendas não estão muito interessados nestes itens porque a associação entre eles já é conhecida. Na realidade, estes especialistas buscam pares de itens dos quais um deles é um produto barato e o outro tem alta taxa de lucro. Nestes casos, lançar uma superpromoção do produto barato faz com que as vendas do produto com alta taxa de lucro aumente.
Em nossa Cesta de Artigos está implícito o padrão de associação entre Queijo e Vinho. Talvez aí, numa campanha de inverno, cadeias de supermercados possam fazer promoções de queijos com o único propósito de vender mais vinhos. Mas como as vendas de ambos eram relativamente baixas, esta regra não satisfez os critérios estabelecidos de \(\mathbf{SupMin}\) e \(\mathbf{ConfMin}\). E, no entanto, é possivelmente este tipo de informação a mais procurada. O que fazer para conseguir minerar as pérolas de informação?
2.10 Lista de Exercícios
(20%) Explique com suas próprias palavras a importância do Suporte Mínimo (\(\mathbf{SupMin}\)) e Confiança Mínima (ConfMin) para a geração de Regras de Associação.
(30%) Explique com suas próprias palavras o que é Conjunto Frequente no contexto das Regras de Associação.
(50%) Crie uma pequena Cesta de Compras (± 5 Exemplos) com itens relacionados ao seu ambiente de trabalho, ou à área de seu TCC, ou a qualquer outra área de seu interesse, e gere as Regras de Associação no Weka. Anexe o respectivo arquivo “
.arff”, e um pequeno relatório sobre a simulação.
2.10.1 🔧 Desafios de Programação (extras)
(Médio) Adicione a métrica Lift à função
apriori()da Prática 4 como critério de filtragem (parâmetrolift_min).(Avançado) Pesquise o algoritmo FP-Growth como alternativa mais eficiente ao Apriori. Quais são as principais vantagens em bases de dados muito grandes?
2.11 Referências do Capítulo
Este capítulo baseou-se nas obras fundamentais que consolidaram as bases da mineração de dados: Agrawal; Imieliński; Swami (1993), para a introdução histórica e formal das regras de associação; Frank; Hall; Witten (2016), como documentação técnica e referência do sistema WEKA; Rocha; Cortez; Neves (2008), Tan; Steinbach; Kumar (2009) e Witten; Frank (2005), para os conceitos estruturais do processo de descoberta de conhecimento (KDD) e algoritmos de mineração; Padhy (2010), para a integração com sistemas inteligentes; e o trabalho clássico de Quinlan (1986), sobre a indução de árvores de decisão.
AGRAWAL, Rakesh; IMIELIŃSKI, Tomasz; SWAMI, Arun. Mining association rules between sets of items in large databases. In: 1993.
FRANK, Eibe; HALL, Mark A.; WITTEN, Ian H. The WEKA Workbench. Online Appendix for "Data Mining: Practical Machine Learning Tools and Techniques". Online; Morgan Kaufmann, 2016. Disponível em: <https://ml.cms.waikato.ac.nz/weka/book.html>
HAN, J.; KAMBER, M. Data Mining: Concepts and Techniques. [S.l.]: Morgan Kaufmann Publishers, 2008.
PADHY, N. P. Artificial Intelligence and Intelligent Systems. [S.l.]: Oxford University Press, 2010.
QUINLAN, Ross. Induction of Decision Trees. [S.l.: S.n.].
ROCHA, Miguel; CORTEZ, Paulo; NEVES, José M. Análise Inteligente de Dados: Algoritmos e Implementação em Java. Lisboa: Editora de Informática, 2008.
TAN, P. N.; STEINBACH, M.; KUMAR, V. Introdução ao Data Mining Mineração de Dados. [S.l.]: Editora Ciência Moderna Ltda., 2009.
WITTEN, I. H.; FRANK, E. Data Mining: Practical Machine Learning Tools and Techniques. [S.l.]: Morgan Kaufmann Publishers, 2005.